Posiblemente hayas visto estos últimos años en linkedin o twitter las típicas imágenes que comparan una situación con otra, y como una está completamente mal y la otra maravillosamente bien según su creador.
Personalmente no soy fan de este tipo de contenido, porque el 90% del mismo o es parcialmente erróneo o es una obviedad clara, así que lo ignoro y ya está, si veo más casos lo que hago es silenciar a quien lo comparte. Pero en este post voy a hablar no solo de esas situaciones, sino de otra que también está siendo muy común en internet últimamente, los benchmarks.
Ojo, no todo este contenido es erroneo, como digo, el 90% en mi opinión lo es, el otro 10% suele ser de muy buena calidad.
1 - Contenido low bait en programación
Hablemos del primero de los casos, donde espero que el autor no se ofenda porque no es un ataque hacia él, simplemente he cogido pues el último que me salió y como llevaba unos días sin hacer un code review pues me he venido arriba.
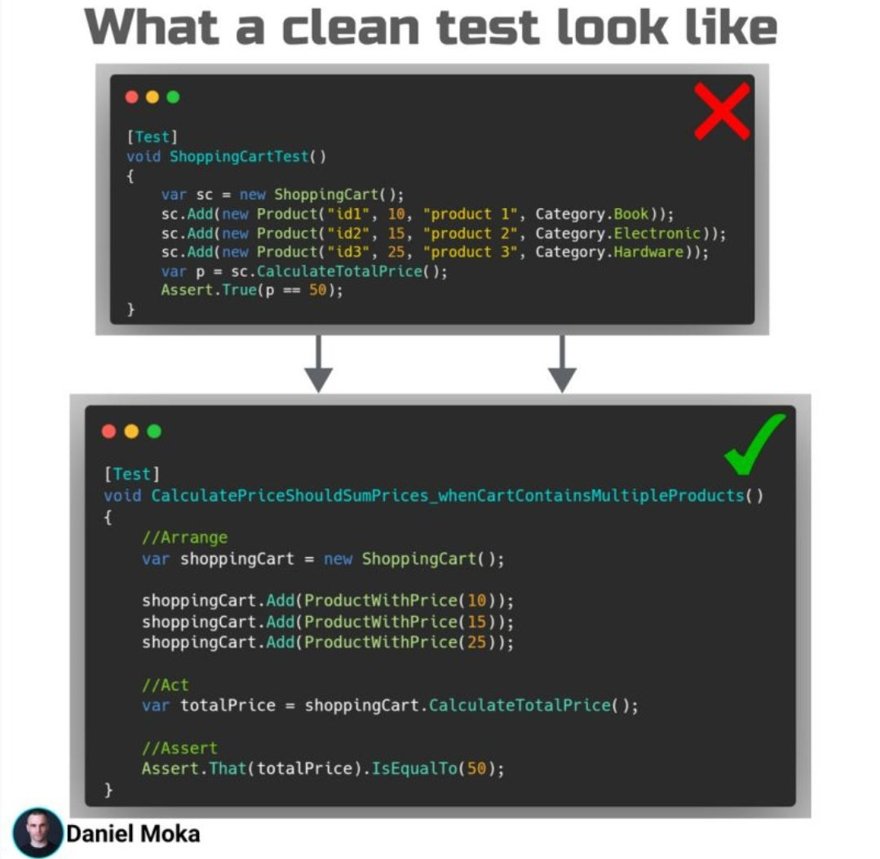
En esta imagen el autor dice que la segunda es un código mucho mejor y mucho más limpio, cosa que de primeras parece cierto.
Pero analicemos qué es lo que ha hecho para que dicho código sea limpio.
- Poner un nombre correcto al test, o eso dice.
- Utilizar una variable con un nombre adecuado.
- Poner AAA y líneas vacías para el espaciado.
Hay más cosas, pero eso es lo que se aprecia a simple vista. Así que vamos a empezar por ello:
Con el nombre del test, está claro que ha mejorado, hemos pasado de uno genérico completamente inservible a uno específico de lo que dicho test hace. En mi opinión, debería ser given_when_then, en este caso al ser simple, ignoramos el given, que en mi opinión esta bien ignorado “CuandoElCarroContieneMultiplesproductos_EntoncesCalcularLaSuma”. Pero el error es claro y manifiesto, ha puesto la frase al reves.
Con el nombre de la variable, pues no hay mucho que decir, esto sí está mucho mejor. Pero es sentido común y personalmente no recuerdo la última vez que vi a alguien poner una o dos letras como nombre de variable.
El uso de AAA, para el que no lo sepa, AAA es arrange, act, assert, que son las tres partes de un test. En mi opinión sobra totalmente, no voy a poner un comentario en una PR de que hay que quitarlo, pero es una anotación totalmente inutil y que no sirve para nada.
Ahora pasemos a analizar el resto del cambio a lo que llama código limpio:
En vez de crear un producto en el propio test, tiene abstraída la creación de los productos en un método. De primeras esto es una buena idea. El problema es que está mal. El método se llama “ProductWithPrice” ni crea en el nombre, ni nada que indique que es lo que hace. Pero no acaba ahí, si os fijáis en el primer ejemplo, el producto tiene los IDs como strings y tiene un nombre y un campo de categoría.
Entonces, ¿Qué ID le pasa a la creación? ¿Qué nombre? ¿Qué categoría? Todo aleatório, o alguna parte está siendo calculada?
En mi opinión si ese método se llamase “CreateDefaultProduct” estaría bien, porque asumes que los valores que no se pasan por parámetros son valores por defecto, pero como no lo está, solo puedo asumir que el ID es el mismo en todos, el nombre es el mismo en todos y la categoría es la misma.
Así que gracias a este nivel de indirección extra, hay dudas.
Fijandonos en las aserciones, la primera, está escrita con el paquete que viene por defecto en C#, y si, es errónea. Pero el motivo por el que es errónea es debido a que está comparando para validar la aserción, NADIE hace esto, NA-DI-E, llevo más de una década programando y he visto de todo, pues esto, no lo he visto nunca.
Si la aserción fuera correcta, con Assert.equal(expected, actual) estaría completamente bien y mucho más clara que la segunda. Porque la segunda utiliza la librería fluentAssertions que esta bien utilizarla, si no fuera porque en este caso estamos añadiendo una dependencia extra para algo que es completamente innecesario. Si se diera el caso de que esa librería es la que se usa en todo el proyecto, pues bien, se puede usar, pero aquí no hay nada que lo indique.
Por no hablar de que el valor esperado de la suma debería estar en una variable y no puesto a pelo ahí en la aserción.
TL;DR: El segundo test es otra puta mierda al nivel del primero.
2 - No os fieis de los benchmarks!
El segundo caso del que quiero hablar es más complejo y está empezando a verse mucho más popular últimamente, que es los benchmarks de diferentes lenguajes.
Voy a hablar en concreto de uno de ellos, el código que hay en GitHub comparando levenshtein distance comparando lenguajes a modo de cual es más rápido.
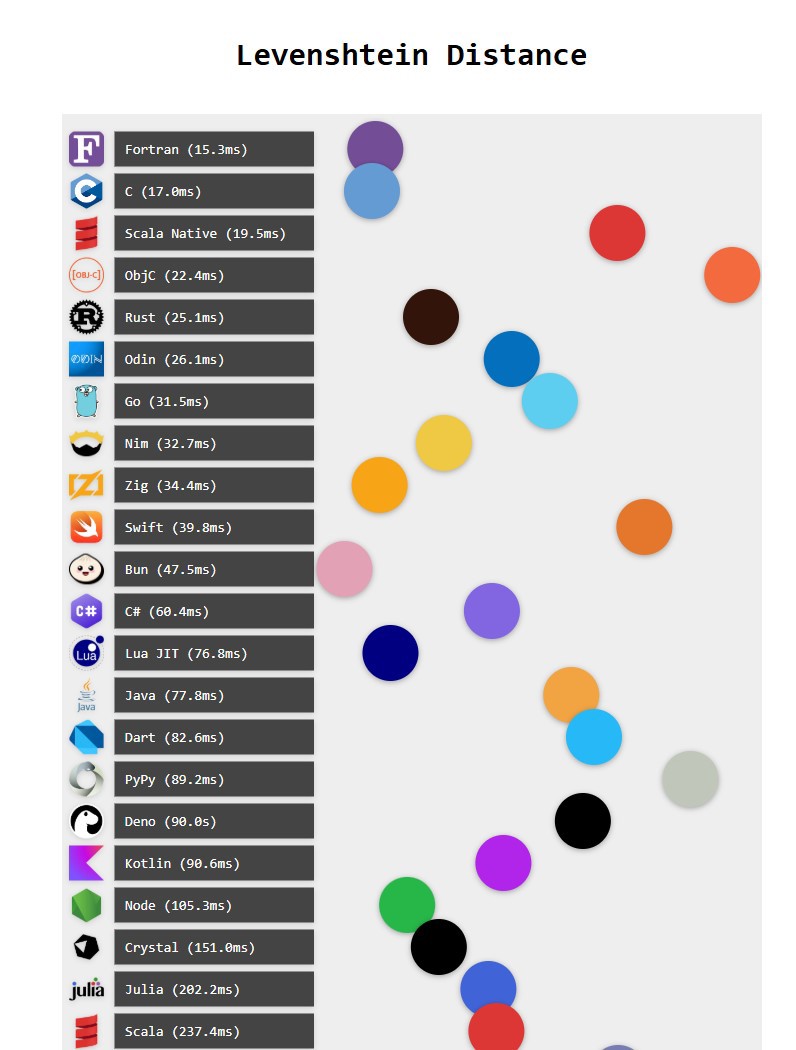 WEb: https://benjdd.com/languages3/ | repo github https://github.com/bddicken/languages
WEb: https://benjdd.com/languages3/ | repo github https://github.com/bddicken/languages
En la web esto es un gráfico muy chulo que se mueve, pero vamos al lío.
De primeras, lo que choca es que el lenguaje más rápido de todos es Fortran, y no solo es el más rápido, ¡Fortan es un 20% más rápido que C!
Así que ya sabéis gente, todos a cambiar de lenguaje y empezar a usar Fortran.
Bromas aparte, Si esto no alerta suficiente a los creadores de dicho benchmark, cualquiera que sepa un poco de Zig o Rust sabrá que el tiempo de ejecución comparado con C será el mismo, con un margen de error, sin embargo, Rust es un 75% más lento y Zig es casi tres veces más lento. ¡Esto no tiene sentido!
Llegados a este punto, sin saber nada más, sobre ningún otro lenguaje de programación, deberíamos suponer que algo no va bien.
Ya no voy a entrar al resto de lenguajes, pero solo mirando los primeros nos damos cuenta de que quien ha hecho esta comparación no sabe programar en dichos lenguajes, y seamos sinceros, a estas alturas de la película todos sabemos que han utilizado inteligencia artificial..
Para ver lo que está mal con este benchmark hay este vídeo (https://youtu.be/EH12jHkQFQk) en inglés de una hora que podeis ver, donde van en detalle sobre cómo llegan a la conclusión pero lo voy a resumir.
Podemos resumir que levenshtein distance compara strings para saber cual es la diferencia entre dos strings (Wikipedia: https://en.wikipedia.org/wiki/Levenshtein_distance).
Para este caso, hay un fichero (https://github.com/bddicken/languages/blob/main/levenshtein/input.txt) con una serie de strings que son más o menos largas, y luego cada lenguaje ejecuta lo que a primera vista es el mismo código.
En el caso del vídeo se compara Fortran con C.
El resultado final, o el motivo del problema es muy simple, en la definición de las variables que van a ser comparadas las declara como strings de 100 caracteres.
character(len=100), allocatable :: args(:)
character(len=100) :: argCodigo (fortran -> code.f90-> lines 93, 94) - Enlace GitHub.
Por lo tanto, la comparación de Fortran únicamente compara 100 caracteres, cuando la más grande son más de 300, lo que hace, que obviamente, vaya más rápido, porque tiene menos que comparar.
Una vez arreglado el bug, la versión de fortran es un 30% más lenta que la de C. Pero va más allá, en el vídeo explican que alguien que domine fortran posiblemente pueda modificar el código para que sea muy similar al de C, ya que hay muchas asignaciones de memoria que parecen innecesarias. Ya que en ambos lenguajes, el bucle principal de la lógica resultaba en el mismo código assembly.
Lo que este pequeño análisis nos deja, es que para este tipo de resultados especialmente en micro-benchmarks el autor no hizo los tests apropiados para verificar que todo funciona exactamente igual. Dando la casualidad que el valor con el que comparaba era exactamente el mismo, y el número de comparaciones era el mismo, directamente lo dieron por bueno, cuando no es así.
Este es un ejemplo de muchos, cuando ves la eficiencia de un lenguaje contra otro siempre tienes que tener en cuenta el dominio de dicha persona en dicho lenguaje, es muy difícil que ambos estén perfectos.
Conclusión
Antes de dar un like, un retweet, un corazón o compartir en linkedin, por favor leer las cosas con atención y analizar lo que hay.
No porque tenga cientos de likes o miles de estrellas en GitHub va a estar bien.
Y por supuesto ojito con fiarse de ciertos benchmarks ya que muchos lenguajes o frameworks se programan intencionadamente para competir en ciertos benchmarks.



