Llevo tiempo queriendo hacer este post, y la verdad es que lo he ido posponiendo debido al parón que quería tomarme de youtube, pero lo que ha pasado esta semana con CrowdStrike ha acelerado el proceso, vamos a ver de lo que estoy hablando.
Índice
1 - El Fatídico final
El primer paso de todos es el que debería ser el último, como hemos llegado a esta situación.
Este viernes 19 de Julio (2024) el mundo entero se ha visto colapsado por un problema causado por CrowdStrike, un software de seguridad que se instala en windows y que muchas empresas tienen, cuando digo muchas es muchas, prácticamente todo el planeta ha sido afectado por este problema, los que vivais en sudamérica o bueno esas franjas horarias seguramente no os hayáis dado cuenta o el impacto sea menor, ya que todo ha empezado a sobre las 12pm en la costa este, lo que se traduce en las 5/6AM en el centro de europa.
Básicamente CrowdStrike ha lanzado una actualización la cual rompe los sistemas windows con un pantallazo azul de la muerte.
Y esto ha afectado a todas las empresas con servidores windows, y que dependen de estas máquinas, tanto Bancos, como Aerolíneas o incluso hospitales se han visto afectados, el usuario de a pie, no lo ha visto pues es una aplicación que no se consume por parte de personas, está más enfocada a la empresa
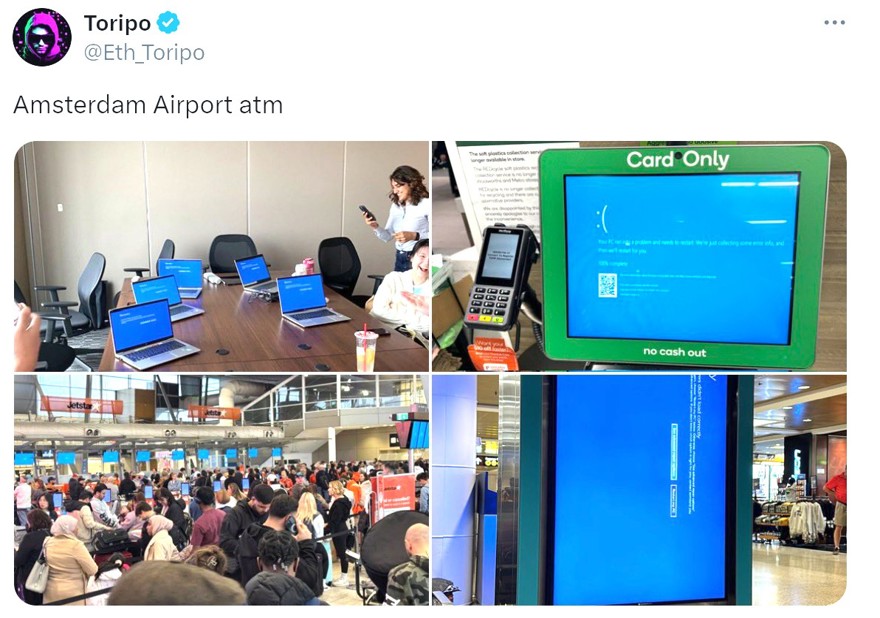
ESto es una imágen del aeropuerto de Amsterdam, donde no se podía hacer nada, todas las pantallas estaban en azul:
Desafortunadamente esto no es un suceso aislado, quizá sí lo sea de tal magnitud, pero hace un par de meses Colossal Order, los desarrolladores del juego Cities Skylines 2 hicieron algo similar, desplegaron una versión que hacía que las oficinas dentro del juego, y principal fuente de ingresos, se vaciaran, haciendo la partida a la que le has metido más de 100 horas sea completamente injugable.
Obviamente no es la misma escala de problema, principalmente porque uno es un juego y el otro afecta a millones de personas, si millones. Pero el motivo o las causas que han llevado a este desenlace son muy similares. Y estas causas son lo importante ya que nos afectan a todos los que trabajamos en software.
2 - Dónde está QA?
QA es el equipo dentro de cada empresa que se encarga de la calidad y de que los cambios de los desarrolladores funcionan como es debido y que no deberían de romper nada.
Si bien es cierto que en empresas pequeñas el propio desarrollador es el que hace QA en empresas más grandes suelen estar separados, eso es porque cuando un desarrollador prueba su propio código sabe como funciona y por tanto no va a intentar romperlo, de forma inconsciente si, pero no lo va a hacer. Por ello, se suele tener otro equipo/personas encargadas de verificar el funcionamiento.
Además cuando hablamos de QA no hablamos únicamente de las personas, también hablamos del proceso que el software debe sufrir antes de ir a producción. Lo que incluye, no solo la revisión, sino también la automatización de la suite de tests o las pruebas manuales.
Y la parte de QA es crucial en el desarrollo de software, si tu empresa no tiene proceso de Calidad mi recomendación es que les pases este blogposts, aunque bueno, hay muchas lecciones aprendidas de lo que ha pasado con CloudStrike.
NOTA: para mi los despliegues en entornos pre producción son parte de QA.
3 - Despliegues a producción
Una vez el proceso de QA ha terminado solo queda desplegar al entorno de producción, y aquí es donde viene la parte más importante que vamos a ver hoy, y el motivo principal por el que quería hacer este post.
Cuando desplegamos hay varias formas de hacerlo, cuál elegir depende entre otros factores del tamaño y número de clientes que tu empresa contenga, no voy a ponerlos todos, pero si voy a poner 3, haciendo referencia a los 3 tamaños de empresa (pequeña/mediana/grande).
3.1 - Despliegue a ciegas / Big bang
Este tipo de despliegues es muy popular en empresas pequeñas donde hay un puñado de empleados y pocos clientes.

Del proceso de QA, el cual ha sido ejecutado por la misma persona que ha hecho el desarrollo, vamos a desplegar a producción y de ahí daremos el ok. Posiblemente sin testear manualmente nada, quizá la persona haya ido a la web si es una web lo que está desplegando y mirar que todo parece que está bien, y ahí da el okey.
Como digo esto es común en empresas pequeñas, y se entiende pues no hay presupuesto para mantener una monitorización constante y el impacto de que algo no funcione por 20 minutos o una hora hasta que alguien te notifica de que no va, no es tan grande como el costo de que en cada despliegue tengas que gastar una hora o dos en monitorizar.
3.2 - Despliegue gradual / rolling
Este tipo de despliegues suceden en empresas de tamaño intermedio, donde ya empezamos a tener réplicas de las aplicaciones detrás de un load balancer, esto quiere decir que tenemos una cantidad más o menos importante de clientes.
Como su nombre indica en este caso vamos a tener un despliegue progresivo o que se ejecuta de forma gradual, qué quiere decir esto?
Que si tenemos 3 instancias de una aplicación vamos a desplegar una, apuntaremos el load balancer a nuestra instancia correremos los endpoints de verificación o healthcheck de que todo está bien (suelen ser /health) y cuando la primera instancia esta bien, damos el Ok para pasar a la siguiente y si falla, cancelamos el despliegue y apuntamos el Load balancer a instancia anterior.
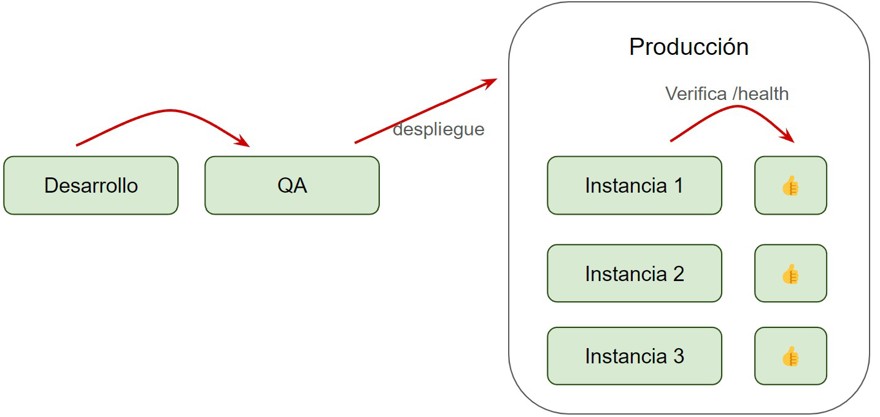
Al terminar todas correremos los tests, y lo más posible es que tengamos un sistema de monitorización y alertas en el sistema los cuales nos notificaran en caso de que algo no vaya bien de forma automática, detectando así el error antes que el usuario final.
3.3 - Despliegue canario / Canary Deployment
Finalmente un tipo de despliegue que es muy costoso en términos humanos y de infraestructura, pero es la forma correcta de hacerlo si tienes millones de clientes.
Vamos a hablar del Canary deployment, lo que significa que vamos a desplegar nuestra funcionalidad a una serie de usuarios y vamos a monitorizar a estos usuarios de forma intensiva, para verificar que todo está bien.
Obviamente esto conlleva muchos recursos tanto de infraestructura, porque hay que montar y mantener la infraestructura para que sea posible, como de personal, porque no es darle a un botón y que todo el proceso se haga solo, sino que tienes que (normalmente) de forma manual, comprobar la estadísticas y los reportes de que todo vaya bien.
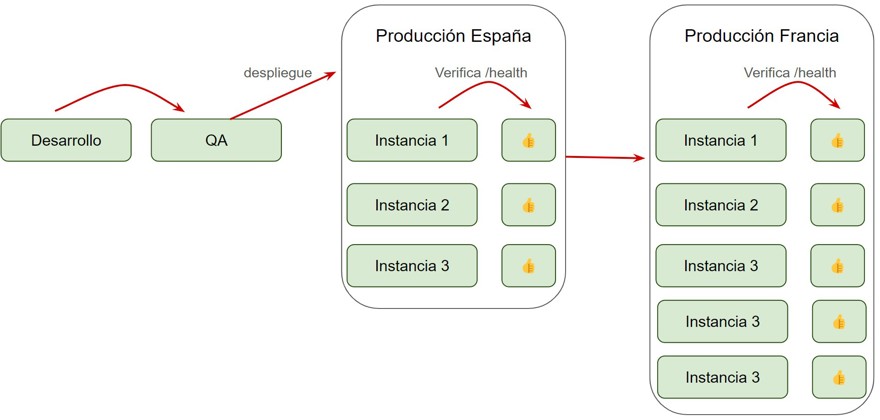
Un ejemplo muy común, pongamos para una empresa con clientes en todas las regiones del mundo, es desplegar el cambio en un único país, España, y una vez verificas que todo está bien en España despliegas al resto de países de europa y posteriormente al resto de continentes.
De esta forma te aseguras de que si algo va mal, únicamente tus usuarios de España se ven afectados en primera instancia. Y tienes varios filtros antes de desplegar a todo el mundo.
No hay que olvidar que además de los despliegues por zonas, también puedes implementar técnicas como el despliegue gradual en cada una de las zonas individuales, lo que da una mayor seguridad.
Por supuesto esto tiene una pega y es que lleva mucho, muchísimo tiempo, habiendo trabajado en los tres tipos de empresa, Canary Deployment parece una pérdida de tiempo, hasta que algo va mal y das gracias a todo por utilizar Canary
El problema de CrowdStrike es que son una empresa con millones de clientes, y deberían utilizar Canary, pero han utilizado un despliegue a ciegas a todo el mundo.
4 - Desplegar en viernes
No quería terminar este post sin deciros que no desplegueis en Viernes si no quieres tener un mal fin de semana.
Esto es obviamente broma, a no ser que tu empresa utilice el primero de los métodos que he explicado para desplegar (o similar) puedes desplegar prácticamente sin problema un viernes.
Eso sí, asegúrate de que todo funciona como es debido y no cojas dos meses de vacaciones justo el día de después como hicieron todos los de Colossal Order con el CS2.

