Este post viene principalmente a raíz de una entrevista que hice hace a principios de 2023 y si bien no diré la empresa si diré que la entrevista técnica era hacer una app que trabajase con kubernetes, antes de ver dicha app, debemos explicar kubernetes.
Índex
Kubernetes da para mil horas de contenido, mi objetivo en este post es que el lector entienda lo que es, y lo que se puede hacer, para que si quiere investigar más, tenga unas bases.
1 - Qué es kubernetes?
Si estás leyendo esto, entiendo que sabes lo que es un contendor y porque son importantes.
Kubernetes es una herramienta que nos permite administrar y automatizar contenedores en la nube.
Esto es muy importante, porque con kubernetes podemos configurar aplicaciones para que escalen y con qué configuraciones queremos que lo hagan.
Por ejemplo, en una web de viajes de España, por la noche, no tenemos apenas tráfico porque todo el mundo está durmiendo, pero por el día tenemos mucho más, por lo que tenemos que aumentar el servidor. Lo mismo sucede antes de las vacaciones de verano, todo el mundo se mete para comprar precios, ahí tenemos que aumentar el servidor otra vez.
Si no entendemos servidor como una única máquina con memoria ram y un procesador sino que lo entendemos como una aplicación completa, entenderemos el concepto mucho más fácil.
Por volver al símil, por la noche, donde todo el mundo está dormido, necesitamos los recursos mínimos para que la app funcione, por ello tenemos nuestro front end (idealmente static deployment) que apunta a una API. Pero no apunta a la api directamente sino que apunta al cluster de kubernetes el cual se encarga de enrutar la llamada al contenedor correcto (utilizando un load balancer) y este es el que apunta a tu contendor que en el caso de kubernetes se les llaman pods:
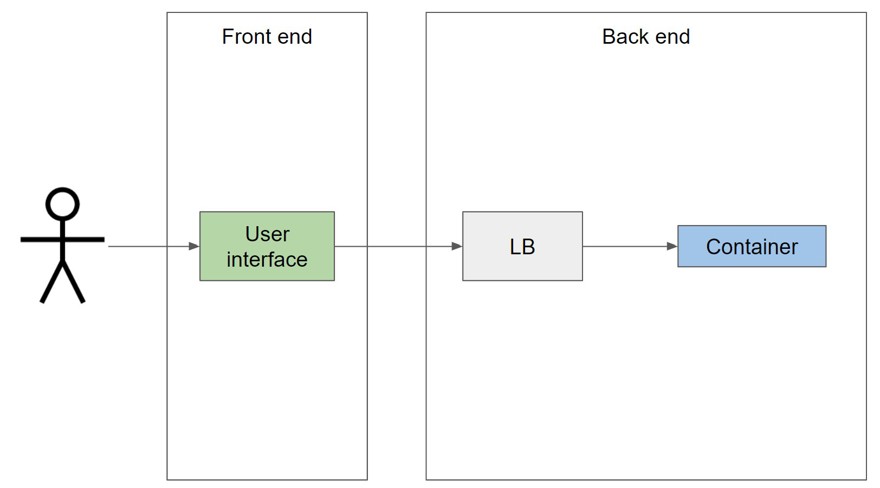
Antes de continuar, en el párrafo anterior he mencionado varios términos, que si bien no es obligatorio saber al detalle como funciona, si que es bueno saber que son:
- Cluster de kubernetes: es un conjunto de nodos que trabajan juntos para ejecutar aplicaciones en contenedores.
- Nodo: Máquinas ya sean individuales o físicas que van a ejecutar los pods.
- Pods: la imagen que vamos a ejecutar. En las empresas que he trabajado, siempre he trabajado con una imagen por pod, pero por poder, se puede poner más de una imagen en un único pod.
- servicios : aunque no lo he mencionado, los servicios existen y permiten a los pods comunicarse entre sí.
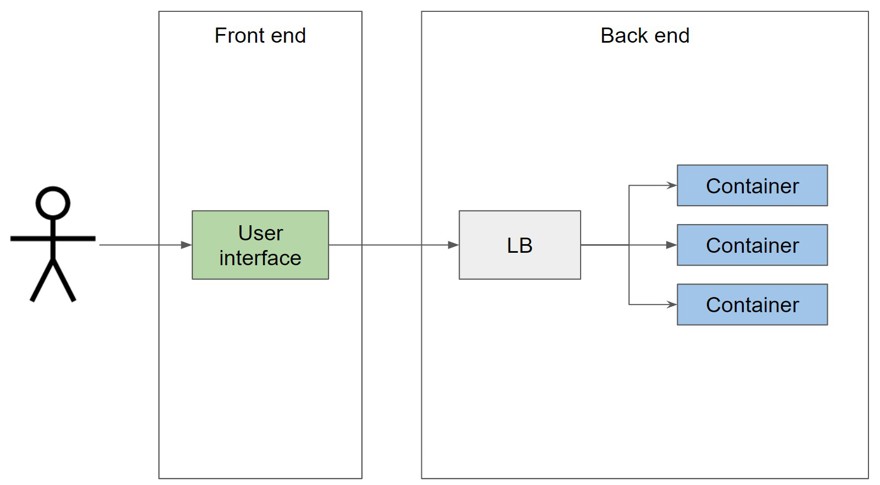
Si volvemos a nuestro caso de uso, durante el día, tenemos mucho más tráfico y necesitamos 3 instancias, para asegurarnos de que todo vaya bien:
Y durante ciertas épocas, donde tenemos más tráfico, necesitamos 5 instancias:
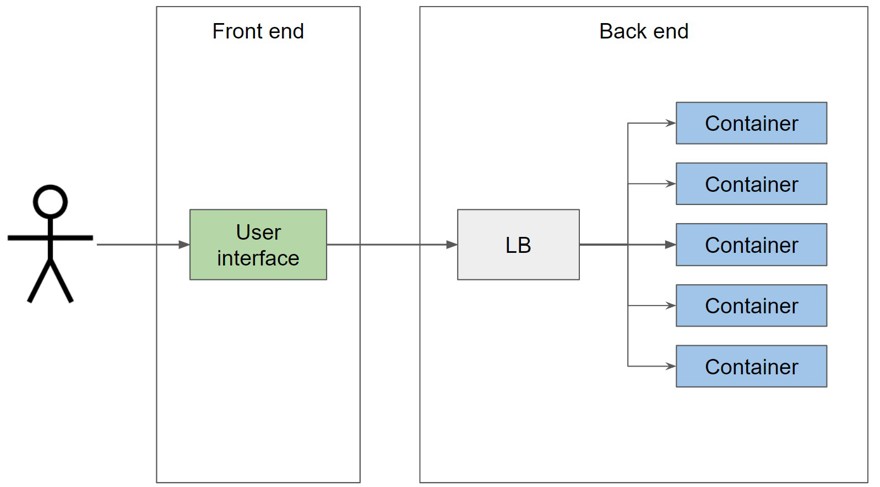
Por lo tanto Kubernetes es la plataforma que administra la infraestructura para realizar los cambios necesarios para que esto sea posible. A este tipo de software se le suele llamar orchestrator.
Kubernetes (también referenciado como k8s) no solo se encarga de el auto-scaling, sino que si un contenedor se rompe por el motivo que sea, se encarga de poner uno nuevo, permitiéndonos así tener alta disponibilidad en las aplicaciones.
Y como desarrolladores esto es lo principal que necesitamos saber sobre k8s.
Voy a mencionar un par de características que yo conozco, pero Kubernetes es un mundo muy grande y complejo que necesita un curso largo para comprenderlo.
1.1 - Qué es ETCD en Kubernetes
ETCD en Kubernetes es una base de datos distribuida tipo clave valor. Y almacena cosas como la configuración, la ubicación de los servicios la coordinación de procesos o los secrets
1.2 - Portabilidad de kubernetes
La gran ventaja en mi opinión y el motivo por el que se utiliza en muchísimas empresas es porque kubernetes se puede ejecutar en todos los proveedores de servicios en la nube o incluso en tu propia máquina.
Además es portabilidad viene a la definición de nuestro Kubernetes la cual se hace con yaml que veremos más adelante.
1.3 - kubernetes en tu máquina local
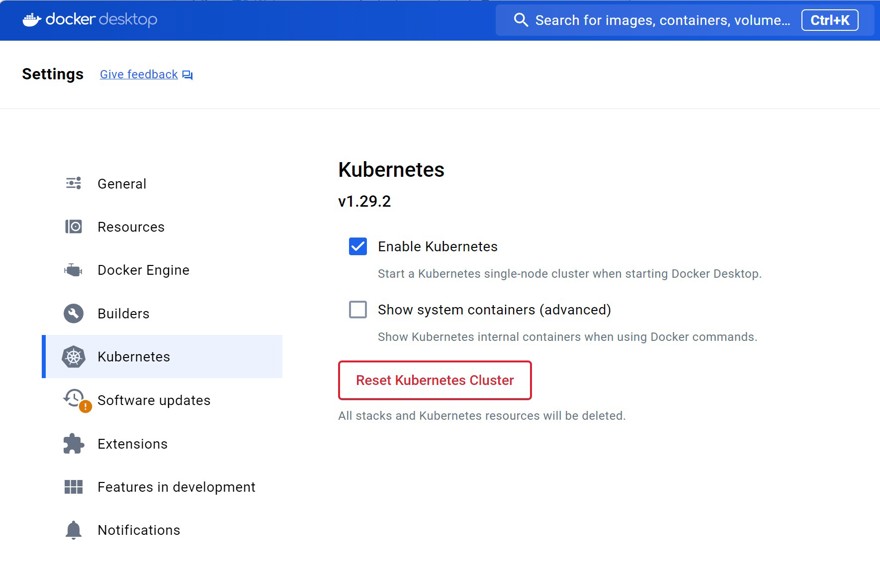
Si estás trabajando en local, la forma mas sencilla de conseguir kubernetes es teniendo docker desktop instalado, que trae kubernetes, aunque tienes que habilitarlo en las opciones:
2 - Kubernetes Manifest
El kubernetes manifest es un fichero que especifica cómo kubernetes va a crear y gestionar un recurso específico de un cluster de kubernetes.
Este fichero puede estar escrito tanto en yaml como en json y describe el estado de los elementos de kubernetes, donde defines el despliegue, réplica, servicio, etc.
Este es el fichero que te va a permitir definir el estado ideal o deseado, por lo que este fichero contiene la configuración que se va a encargar de escalar tu aplicación cuando sea necesario.
2.1 - Partes de un kubernetes manifest
El fichero se basa en 4 partes:
- apiVersion: define la versión de la api a utilizar.
- Kind: define el tipo de objeto que estás definiendo, ya sea un pod, despliegue o un servicio.
- Metadatos(metadata): incluye las etiquetas nombres y anotaciones.
- Especificación(spec): define el estado deseado de un objeto de kubernetes, así como sus propiedades y las configuraciones.
- Estado: describe el estado de un objeto, el número de réplicas y la versión.
Luego cada servicio específico que utilices puede tener diferentes especificaciones
2.2 - Ejemplo de fichero de k8s
Ahora vamos a pasar a un ejemplo de un fichero, en este caso lo veremos con MySQL porque al final la base de datos es un elemento de la gran mayoría de infraestructuras que tenemos ahí fuera.
La primera parte es definir el PersistentVolume, aquí definimos el volumen físico del nodo que se utiliza para almacenar los datos de MySQL, en este caso en el disco, en la ruta que está definida en el hostpath. Si utilizas AWS, AZURE,Google Cloud, etc aquí es donde definimos la configuración
apiVersion: v1
kind: PersistentVolume
metadata:
name: mysql-pv
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/mnt/data/mysql"En el mismo fichero, definimos el PersistentVolumeClaim, el cual solicita un volumen con la cantidad de almacenamiento especificada. En nuestro caso, hacemos referencia al PersistentVolume que hemos creado.
apiVersion: v1
kind: PersistentVolume
metadata:
name: mysql-pv
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/mnt/data/mysql"
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mysql-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1GiPasamos a la definición del servicio que queremos utilizar, en nuestro caso mysql, aquí definimos como un pod está expuesto al exterior, y asegura la comunicación con el pod.
Igual que en docker, si tienes un puerto de tu máquina ocupado, como puede ser el de por defecto de mysql, puedes utilizar uno y k8s se encarga de redireccionar del de tu máquina al del pod.
apiVersion: v1
kind: PersistentVolume
metadata:
name: mysql-pv
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/mnt/data/mysql"
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mysql-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
---
apiVersion: v1
kind: Service
metadata:
name: mysql
spec:
ports:
- port: 5306
targetPort: 3306
protocol: TCP
selector:
app: mysql
clusterIP: None
Finalmente el deployment, contiene toda la información interna del contenedor. En nuestro caso estamos indicando que imagen con que versión (mysql versión 5.7), las variables de entorno, el puerto y los volúmenes que vamos a utilizar, que hacen referencia a los creados al principio.
apiVersion: v1
kind: PersistentVolume
metadata:
name: mysql-pv
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/mnt/data/mysql"
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mysql-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
---
apiVersion: v1
kind: Service
metadata:
name: mysql
spec:
ports:
- port: 5306
targetPort: 3306
protocol: TCP
selector:
app: mysql
clusterIP: None
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: mysql
spec:
selector:
matchLabels:
app: mysql
strategy:
type: Recreate
template:
metadata:
labels:
app: mysql
spec:
containers:
- image: mysql:5.7 #arm64v8/mysql
name: mysql
env:
- name: MYSQL_ROOT_PASSWORD
value: "your-root-password"
ports:
- containerPort: 3306
name: mysql
volumeMounts:
- name: mysql-storage
mountPath: /var/lib/mysql
volumes:
- name: mysql-storage
persistentVolumeClaim:
claimName: mysql-pvc
Podemos tener todas las definiciones en un único fichero, si separamos cada una de ellas con “---” o podemos tener un fichero para cada definición.
En mi opinión, depende de lo grande que sea tu sistema, merece la pena, o no, tener un único fichero en vez de muchos, si tienes 10 servicios, ten múltiples ficheros, si tienes una base de datos y una app, se puede hacer con uno solo.
Si guardas esta información en un fichero llamado deployment.yaml puedes ejecutarlo con el siguiente comando
kubectl apply -f deployment.yaml
Y te dará un resultado como el siguiente:
persistentvolume/mysql-pv created
persistentvolumeclaim/mysql-pvc created
service/mysql created
deployment.apps/mysql created
Si ahora haces kubectl get pods deberías poder ver la imagen a la que te puedes conectar sin problemas:

Y si como yo, usas docker desktop, también puedes verlo ahí:

3 - Qué es helm
Finalmente tenemos Helm, que si vamos a su repo de github vemos que es un gestor de paquetes preconfigurados para kubernetes, a los cuales se les llama Charts.
Un chart no es más que la combinación de todo lo que hemos visto en el punto anterior, osea todo lo que una aplicación requiere para funcionar correctamente y ser desplegada como una unidad.
Entonces, en vez de tener toda esa configuración que hemos mostrado, únicamente necesitamos hacer helm install stable/mysql
Ese paquete Helm contiene todo lo necesario para que la app funcione.
Otra de las funcionalidades de helm es que soporta plantillas y variables, por lo que si trabajas con kubernetes en tu empresa, lo normal es que tengas un helm chart para las apps de back end y otro helm chart para las de front end, las cuales contienen variables que van a permitir indicar la imagen, el nombre, o el número de réplicas. Ahorrando así muchísima configuración y dejando únicamente un puñado de líneas de configuración en cada uno de los repositorios, dicha configuración será pasada a la plantilla y todas las apps funcionan de la misma manera.
4 - Debo aprender kubernetes como desarrollador
Es importante tener un conocimiento mínimo de kubernetes si trabajas como desarrollador de la parte back end o full stack, más que nada porque en la gran mayoría de empresas se trabaja con contenedores y el conocimiento que puedas aprender sobre dichos contenedores siempre te puede venir bien.
Ahora, ir más allá hacia un extremo donde te lo sepas todo de memoria tampoco lo veo necesario, con saber los comandos básicos para ver los pods o leer logs junto con ser capaz de entender la documentación te debería ser suficiente como desarrollador. Si vas más allá y aprendes k8s bien (aunque no se si alguien sabe kubernetes bien en el mundo) te vas a convertir en un híbrido entre desarrollador y DevOps que está muy bien y se paga muy bien 😉.

