En este post vamos a ver una forma de programar un tanto funcional, en la cual, mezclamos programación funcional con programación orientada a objetos y esta forma o patrón se lo debemos a Scott Wlaschin que fue su autor original y puedes encontrar más información en su página web fsharpforfunandprofit.
Lo primero que debemos entender antes de comenzar es cómo funciona nuestro código en un caso de uso normal, para este ejemplo vamos a simular el caso de uso de la creación de un usuario nuevo en el sistema.
Y comprender que NO hace falta experiencia en programación funcional para aplicar este patrón.
Índice
1 - Caminos a seguir
A - Camino feliz (Happy path)
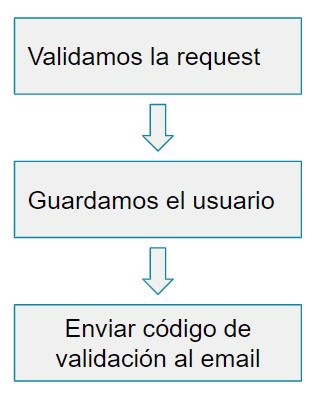
Como siempre empezamos nuestro diseño pensando en cuál es el camino correcto a seguir para completar la tarea, para nuestro caso en particular es muy sencillo, validamos el usuario, guardamos el usuario y enviamos un código de verificación al email.
public string BasicAccountCreation(Account account)
{
ValidateNewAccount(account);
SaveUser(account);
SendCode(account);
return "Usuario anadido correctamente";
}
B - Camino infeliz (Non happy path)
Por supuesto los usuarios no siempre siguen “las reglas” o quizá ya estén registrados, en estos casos debemos de controlar los errores, para evitar tener el mismo usuario duplicado en la base de datos por ejemplo.
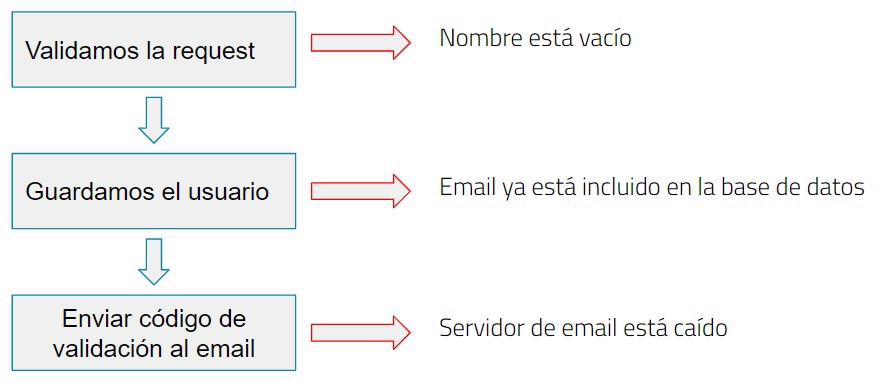
Como vemos podemos tener diferentes errores en puntos diferentes de nuestra aplicación, una implementación común de el control de errores en programación orientada a objetos:
public string BasicAccountCreation(Account account)
{
string accountValidated = ValidateNewAccount(account);
if(!string.IsNullOrWhiteSpace(accountValidated))
{
return accountValidated;
}
bool isSaved = SaveUser(account);
if(!isSaved)
{
return "Error actualizando la base de datos";
}
bool isSent = SendCode(account);
if(!isSent)
{
return "Error Enviando el email";
}
return "Usuario anadido correctamente";
}Como vemos un montón de código, sencillo de seguir en este caso pero en caso de tener muchas más validaciones se nos puede hacer bastante complejo.
Si analizamos estos flujos en sus respectivos pasos vemos que el resultado es el siguiente; Para el happy path, todo va bien, y todo funciona por lo que tenemos un punto de entrada y uno de salida.
Mientras que para analizar los fallos, tenemos varios puntos de ruptura en nuestro código.
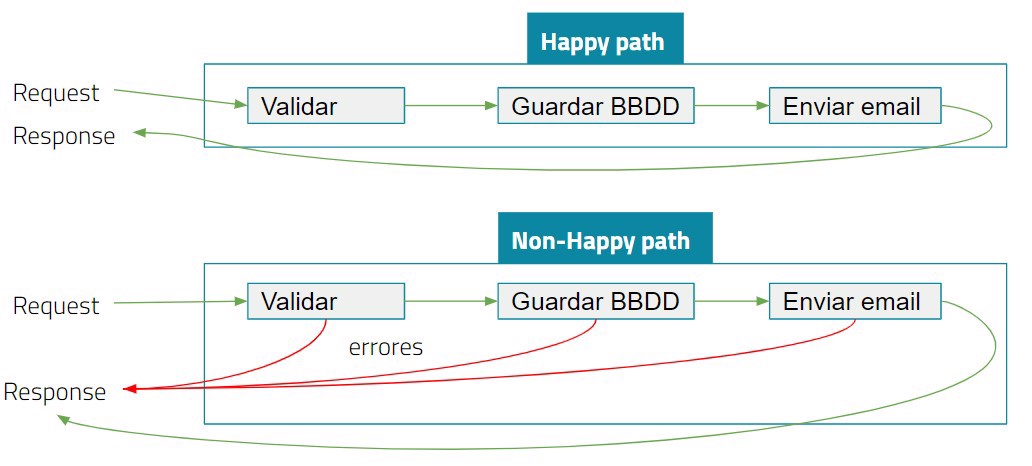
Como está indicado al principio del post la idea principal de este patrón es mezclar lo mejor de la programación funcional dentro de nuestras aplicaciones orientadas a objetos.
Para ello analizamos el mismo proceso, pero esta vez haciendo un análisis o flow funcional
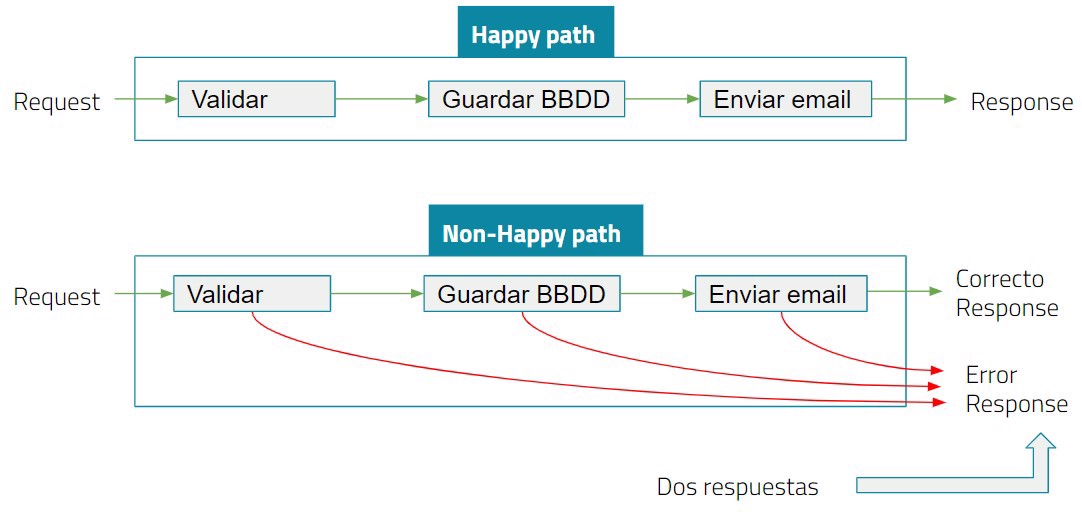 Esta es la representación funcional, observamos que el flujo es similar pero no igual, ya que en este escenario tenemos no solo una respuesta, sino dos al final de nuestro proceso.
Esta es la representación funcional, observamos que el flujo es similar pero no igual, ya que en este escenario tenemos no solo una respuesta, sino dos al final de nuestro proceso.
2 - Diseño funcional
Para conseguir que nuestra aplicación nos devuelva dos resultados, lo que tenemos que hacer es un objeto que contenga ambos objetos.
Pero, antes de ponernos a programar como locos debemos entender los pasos a seguir, ya que, no es simplemente un único error que podemos tener, sino, que podemos tener varios.
Basándonos en nuestro “non happy path” disponemos del siguiente camino
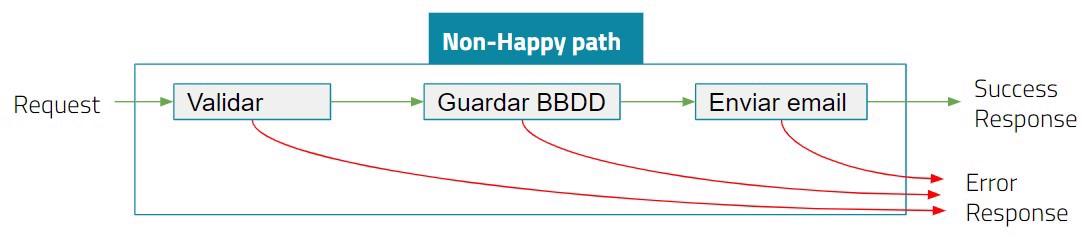 Como observamos los errores son 3, un error en la validación, un error en la base de datos y un error en el servidor de correo.
Como observamos los errores son 3, un error en la validación, un error en la base de datos y un error en el servidor de correo.
Por lo que el objeto resultante sería algo como lo siguiente, un objeto dentro que contiene “success” y los errores.
type result =
Success
|| ErrorValidacion
|| ErrorBaseDeDatos
|| ErrorSMTPServerObviamente este código no es el final, ya que está focalizado en este caso de uso en concreto. Para ello lo podemos comprimir aún más y es que si agrupamos los errores, ya sea en una lista o un objeto error que contenga dentro la lista nuestro objeto pasará a tener únicamente dos propiedades independientes del caso de uso en el que estamos.
type result =
Success
|| ErrorEsta solución no es correcta al 100% ya que devolvemos que ha funcionado pero no devolvemos ningún elemento únicamente los fallos. Si queremos devolver el elemento lo que debemos hacer es implementar generics y de esta forma podemos hacer de Success<T> el cual T es el tipo que queremos devolver.
Type result<T> =
Success of T
|| Error
3 - Objetivo del patrón
Una vez tenemos claro el patrón y lo que hace cúal es su objetivo, podemos definir que tenemos varios objetivos
- Combinar todos los errores en un único sitio.
- Crear funciones más pequeñas.
- Mostrar el flujo de datos.
- Una única función por cada caso de uso.
4 - Cómo funciona el patrón Result (Railway Oriented programming)
Debemos entender también cómo funciona, en el punto dos hemos visto que el objetivo principal es hacer un wrapper del tipo que queremos devolver (Result<T>) , pero porque.
Aquí es donde entra la parte de programación funcional. Básicamente Result<T> va a hacer que el Tipo T cambie constantemente (o no, depende de la lógica) pero para verlo más claro, pongo la analogía de; Tenemos un coche, que entra en una función y sale una bici, de esa bici entra en otra función y sale un barco, por ejemplo.

Es sencillo, el tipo de entrada de una función debe ser el tipo de salida de la función anterior.
4.1 - Comparación
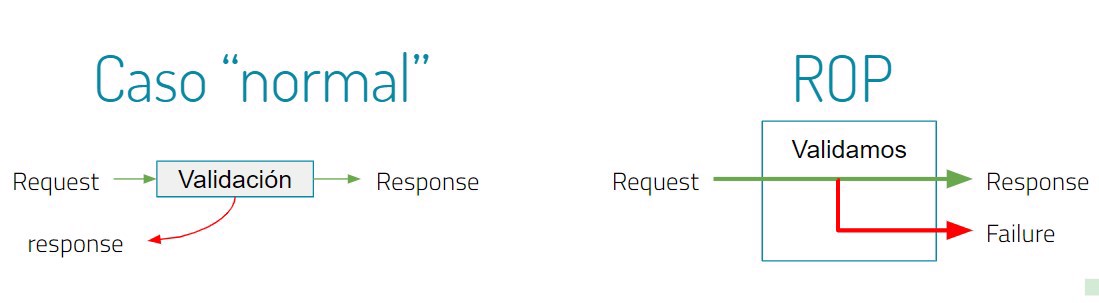
En comparación con lo que sería una comprobación normal donde tenemos nuestra comprobación y si no cumple hacemos un return, no siempre realizamos un return pero el programa no continúa, sino que vuelve hacia atrás, en nuestro nuevo patrón si “continúa” y lo pongo entre paréntesis porque lo que de verdad hace es saltarse todas las funciones que vienen después de nuestro fallo.
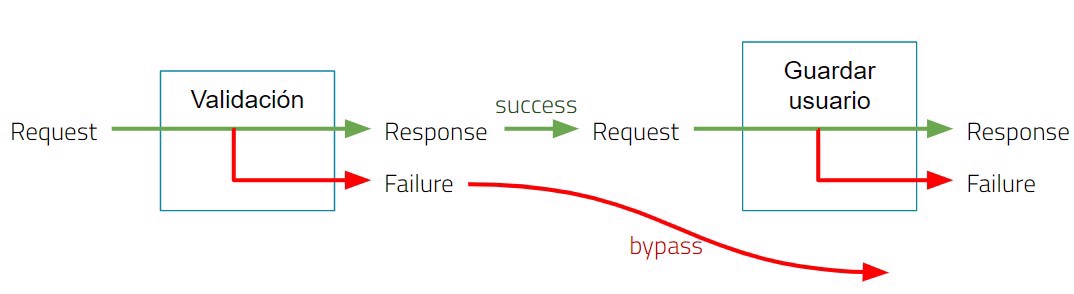
Para ver un poco más en detalle cómo funciona, en cada método recibimos ambos parámetros de entrada, tanto el correcto como el fallido. Mientras todo siga correcto, nuestra función seguirá ejecutando las los métodos de una forma normal. mientras que si lanzamos un error en cualquier momento se nos pasará a la parte del fallo.
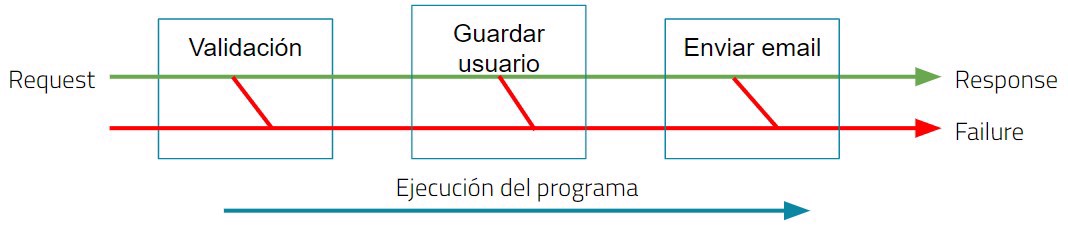
Como vemos tenemos “dos” input y dos posibles salidas. Cada una de las conexiones entre dos métodos se realizan a través de un binding el cual controlara si lo que estamos ejecutando es el camino feliz o el camino de los fallos.
5 - Cómo aplicar ROP en C#
El patrón se basa principalmente en una clase, la cual llamaremos Result<T> por lo tanto lo primero que vamos a hacer es un struct que contenga nuestro Result<T> y por supuesto, los errores.
Otro dato a tener en cuenta es que puede ser que en nuestro código, tengamos métodos que devuelven void estos métodos no son compatibles con el nuevo patrón ya que como hemos visto en los puntos anteriores cada método debe devolver un tipo, para este caso en concreto disponemos del tipo Unit el cual no hace nada, simula void.
public sealed class Unit
{
public static readonly Unit Value = new Unit();
private Unit() { }
}
public struct Result<T>
{
public readonly T Value;
public static implicit operator Result<T>(T value) => new Result<T>(value);
public readonly ImmutableArray<string> Errors;
public bool Success => Errors.Length == 0;
public Result(T value)
{
Value = value;
Errors = ImmutableArray<string>.Empty;
}
public Result(ImmutableArray<string> errors)
{
if (errors.Length == 0)
{
throw new InvalidOperationException("debes indicar almenso un error");
}
Value = default(T);
Errors = errors;
}
}Si observamos el código de cerca, disponemos de Result<T> que contiene T con el tipo que pasamos, y los errores.
nota: los errores son un simple string para simplificar el ejemplo, pero podríamos tener un tipo “Error” con códigos, etc.
Todo el trato de este patrón es llevado a través de extension methods de esta forma podemos definir cuando es `Success` o `Failure`.
public static class Result
{
public static readonly Unit Unit = Unit.Value;
public static Result<T> Success<T>(this T value) => new Result<T>(value);
public static Result<T> Failure<T>(ImmutableArray<string> errors) => new Result<T>(errors);
public static Result<T> Failure<T>(string error) => new Result<T>(ImmutableArray.Create(error));
public static Result<Unit> Success() => new Result<Unit>(Unit);
public static Result<Unit> Failure(ImmutableArray<string> errors) => new Result<Unit>(errors);
public static Result<Unit> Failure(IEnumerable<string> errors) => new Result<Unit>(ImmutableArray.Create(errors.ToArray()));
public static Result<Unit> Failure(string error) => new Result<Unit>(ImmutableArray.Create(error));
}El código no tiene mayor misterio, simplemente llamamos a success o failure cuando lo deseamos y nos crea el tipo Result<T>.
5.1 - Construcción del entorno para el patrón ROP
Y ahora vamos a ver como crear el método que va decidir si la ejecución del programa debe ir por el camino feliz o saltarse los métodos para ir al final directamente.
En este post vamos a ver la creación del método .Bind(). Para ello volvemos a hacer uso de los extension methods en conjunto con los delegados ya que nuestro método Bind va a recibir por parametro un delegado, osea, un método.
public static class Result_Bind
{
public static Result<U> Bind<T, U>(this Result<T> r, Func<T, Result<U>> method)
{
try
{
return r.Success
? method(r.Value)
: Result.Failure<U>(r.Errors);
}
catch (Exception e)
{
ExceptionDispatchInfo.Capture(e).Throw();
throw;
}
}
}Podemos analizar el código, y como vemos es un simple if en un operador ternario, si nuestro r (result) es Succes, lo que quiere decir que la lista de errores está vacía, ejecuta el método que pasamos por parámetro, si no, crea un objeto con los errores.
5.2 - Ampliación del entorno para el patrón ROP
Para este ejemplo no he querido complicar mucho los métodos, actualmente funciona de forma síncrona, si quisiéramos que funcionase asíncronamente deberíamos añadir Task<T> tanto al valor devuelto por el método como a los parámetros de entrada, y por supuesto esperar a que el resultado este completo haciendo un await.
O si por ejemplo quisiéramos crear un método .Then() el cual ignora el resultado del delegado, en este caso un delegado Action, y devuelve el valor de entrada.
O un .Map() donde mapeamos de un valor a otro.
public static async Task<Result<U>> Bind<T, U>(this Task<Result<T>> result, Func<T, Task<Result<U>>> method)
{
try
{
var r = await result;
return r.Success
? await method(r.Value)
: Result.Failure<U>(r.Errors);
}
catch (Exception e)
{
ExceptionDispatchInfo.Capture(e).Throw();
throw;
}
}
public static Result<T> Then<T>(this Result<T> r, Action<T> action)
{
try
{
if (r.Success)
{
action(r.Value);
}
return r;
}
catch (Exception e)
{
ExceptionDispatchInfo.Capture(e).Throw();
throw;
}
}
public static Result<U> Map<T, U>(this Result<T> r, Func<T, U> mapper)
{
try
{
return r.Success
? Result.Success(mapper(r.Value))
: Result.Failure<U>(r.Errors);
}
catch (Exception e)
{
ExceptionDispatchInfo.Capture(e).Throw();
throw;
}
}
6 - Caso de uso
El código está disponible en github.
Nota: el código es síncrono para simplificar.
6.1 - Creación de un usuario utilizando POO
Para el ejemplo he creado un caso de uso o servicio, al cual vamos a simular que añadimos un usuario en nuestra base de datos. Primero realizaremos el servicio en programación orientada a objetos:
public interface IAddUserPOOServiceDependencies
{
bool AddUser(UserAccount userAccount);
bool EnviarCorreo(UserAccount userAccount);
}
/// <summary>
/// Añadir el usuario utilizando una estructura de programación orientada a objetos.
/// </summary>
public class AddUserPOOService
{
private readonly IAddUserPOOServiceDependencies _dependencies;
public AddUserPOOService(IAddUserPOOServiceDependencies dependencies)
{
_dependencies = dependencies;
}
public string AddUser(UserAccount userAccount)
{
var validacionUsuario = ValidateUser(userAccount);
if (!string.IsNullOrWhiteSpace(validacionUsuario))
{
return validacionUsuario;
}
var addUserDB = AddUserToDatabase(userAccount);
if (!string.IsNullOrWhiteSpace(addUserDB))
{
return addUserDB;
}
var sendEmail = SendEmail(userAccount);
if (!string.IsNullOrWhiteSpace(sendEmail))
{
return sendEmail;
}
return "Usuario añadido correctamente";
}
private string ValidateUser(UserAccount userAccount)
{
if (string.IsNullOrWhiteSpace(userAccount.FirstName))
return "El nombre propio no puede estar vacio";
if (string.IsNullOrWhiteSpace(userAccount.LastName))
return "El apellido propio no puede estar vacio";
if (string.IsNullOrWhiteSpace(userAccount.UserName))
return "El nombre de usuario no debe estar vacio";
return "";
}
private string AddUserToDatabase(UserAccount userAccount)
{
if (!_dependencies.AddUser(userAccount))
{
return "Error añadiendo el usuario en la base de datos";
}
return "";
}
private string SendEmail(UserAccount userAccount)
{
if (!_dependencies.EnviarCorreo(userAccount))
{
return "Error enviando el correo al email del usuario";
}
return "";
}
}Como vemos tenemos varios problemas, primero, que al devolver un único tipo (en este caso un string) estamos limitando el valor que podemos devolver, queremos comprobar múltiples validaciones, pero sólo podemos devolver una a una.
Podríamos arreglar este problema si en vez de devolver un único string, devolvemos una lista List<string> pero en ese caso, si todo funciona correctamente, estaremos creando una lista cuando únicamente necesitamos un único valor.
Además de este problema, tenemos que es más o menos difícil de leer, en este caso de uso únicamente debemos comprobar un par de elementos y aún así se nos queda una clase muy larga y difícil de leer. Pero el código funciona, sin mayor problema, el método principal AddUser no es estéticamente bonito pero hace la función.
6.2 - Creación de un usuario utilizando ROP
Ahora vamos a realizar el mismo proceso, pero utilizando el patrón de “Railway oriented programming” que hemos estado viendo durante este post.
Antes de continuar, recordar que este caso de uso se trata de utilizar nuestro tipo Result<T> he cambiado un poco la interfaz con las dependencias para implementar también nuestro nuevo patrón.
Y esta sería nuestra implementación:
public interface IAdduserROPServiceDependencies
{
Result<bool> AddUser(UserAccount userAccount);
Result<bool> EnviarCorreo(string email);
}
public class AdduserROPService
{
private readonly IAdduserROPServiceDependencies _dependencies;
public AdduserROPService(IAdduserROPServiceDependencies dependencies)
{
_dependencies = dependencies;
}
public Result<UserAccount> AddUser(UserAccount userAccount)
{
return ValidateUser(userAccount)
.Bind(AddUserToDatabase)
.Bind(SendEmail)
.Map(_ => userAccount);
}
private Result<UserAccount> ValidateUser(UserAccount userAccount)
{
List<string> errores = new List<string>();
if (string.IsNullOrWhiteSpace(userAccount.FirstName))
errores.Add("El nombre propio no puede estar vacio");
if (string.IsNullOrWhiteSpace(userAccount.LastName))
errores.Add("El apellido propio no puede estar vacio");
if (string.IsNullOrWhiteSpace(userAccount.UserName))
errores.Add("El nombre de usuario no debe estar vacio");
return errores.Any()
? Result.Failure<UserAccount>(errores.ToImmutableArray())
: userAccount;
}
private Result<string> AddUserToDatabase(UserAccount userAccount)
{
return _dependencies.AddUser(userAccount)
.Map(_ => userAccount.Email);
}
private Result<bool> SendEmail(string email)
{
return _dependencies.EnviarCorreo(email);
}
}Antes de pasar a explicar el código más en detalle quiero mostrar la cantidad de código que se ha visto reducida, tener menos código implica, normalmente, tener un código más limpio y fácil de entender.
El método principal AddUser es mucho más pequeño y fácil de entender, como vemos estamos haciendo uso de nuestro método .Bind para llamar a cada uno de los métodos que queremos llamar y al final de la secuencia llamamos al método .Map el cual actuará en caso de que todo sea correcto, devolviendo la cuenta de usuario.
El método Validateuser es el que más ha cambiado, ya que al ser el primero que se ejecuta, es donde creamos nuestro Result<T> que crearemos como success si va todo bien y como failure si hay algún error.
Los métodos AdduserToDatabase y SendEmail siguen realizando la misma función pero ahora SendEmail únicamente recibe un string email, esto es intencionadamente, para mostrar que la salida del método anterior es la entrada del método siguiente.
En estos métodos no necesitamos comprobar los errores porque la dependencia (interfaz) nos devuelve Result<T> por lo que en caso de haber algún error, estará capturado cuando hacemos el .Map() o el .Bind() en la función principal.
Conclusión
En este post hemos visto cómo mezclar programación funcional y programación orientada a objetos de una manera que nos ayuda mucho en la limpieza de código y particularmente a la hora de controlar los errores.
Personalmente recomiendo el uso de este patrón ya que se hace mucho más sencillo programar. De hecho, esta web está escrita entera con este patrón. Utilizarlo me ha permitido tener un código mucho más limpio y cuando tengo que cambiar algo, apenas tardó tiempo en leer que es lo que hace el código y entenderlo a la perfección.
El código de este ejemplo está en GitHub, te invito a cogerlo y probarlo en alguno de tus proyectos, durante los próximos días/semanas iré ampliando la funcionalidad, como por ejemplo permitir todos los métodos asíncronos. En cualquier caso, si tienes alguna idea de mejora puedes hacer una Pull Request.
Si te ha gustado el contenido por favor comparte (menú de la izquierda)



