Hoy vengo a hablar sobre la que para mí es la arquitectura ideal para una aplicación.
A diferencia de otros post donde soy completamente objetivo, aquí vamos a ver mi opinión y porque me gusta y qué beneficios trae o no trae, ya que muchos me preguntáis qué cuál es la arquitectura que yo utilizo.
Índice
1 - Qué es la Arquitectura Core-Driven?
Entiéndase que voy a hablar dentro del entorno profesional o de aplicaciones grandes, si quieres hacer un pequeño script o una pequeña funcionalidad que hace X no lo haría así, para eso te haces un script.
Pero vayamos al lío. En este canal hemos visto diferentes arquitecturas, mvc, clean, vertical slice, o hexagonal y si bien es cierto yo no tengo una predefinida lo que sí que hago es mezclar un poco todo para yo trabajar de una forma cómoda que al final es lo importante.
Seguramente esta arquitectura se parezca a otra en un 90%, pero en verdad hay tantas que no sale a cuenta discutir, lo que importa no es el nombre, que al final me lo he inventado mientras escribía el post, si no el concepto.
2 - Separación de Responsabilidades en una Arquitectura Core-Driven
Lo que más llevo a rajatabla es la separación de responsabilidades.
Con esto quiero decir que dentro de cada aplicación voy a tener diferentes capas y cada capa tiene una responsabilidad clara.
Es una mezcla entre clean architecture, hexagonal y layered, porque tenemos una capa donde el negocio es lo más importante (CA) y luego utilizamos dependencias a través de interfaces (puertos y adaptadores de hexagonal), además de la propia separación entre capas y la dirección hacia el interior que comparte con layered.
Por ejemplo, en una api tendríamos lo siguiente:
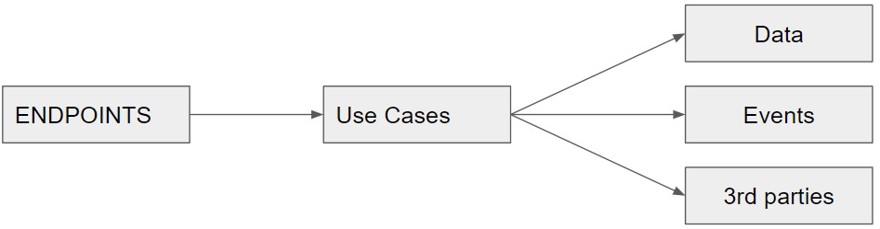
En caso de que trabajes en C#, puedes utilizar carpetas o proyectos dentro de una solución. Personalmente me da igual mientras estén separados y tenga una clara división.
2.1 - Punto de entrada de la aplicación
Como podemos ver tenemos el endpoint que lo único que está haciendo es ser un proxy entre la llamada y el caso de uso que vamos a ejecutar, la función del endpoint es enrutar y comprobar la autorización. Trabajar lo que sea que tengamos en la request pipeline, configuración de OpenAPI, en resumen, solo elementos relacionados con ser una api están en este punto.
Lo que significa que si en vez de ser una API, es un consumidor de arquitecturas distribuidas, el único cambio es que no tendremos un endpoint que lance la acción, sino un handler que lea un evento, comprobar que no hemos procesado dicho evento etc.
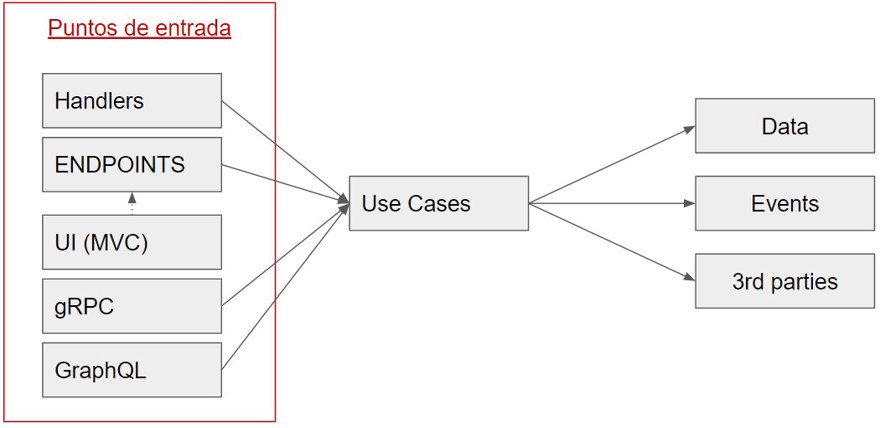
Exactamente lo mismo pasa en la interfaz, si usamos MVC puede ser que sea la interfaz quien lance la llamada al controlador correspondiente.
Lo importante es saber que esta capa es el punto de entrada desde el exterior hacia nuestra aplicación y actúa como tal.
2.2 - Capa de casos de uso
La capa intermedia es la más importante, porque es la que va a contener la capa de la lógica de negocio y es la que de verdad debemos testear. Esta capa va a hacer todas las comprobaciones necesarias, todas las acciones que nuestro caso de uso requiera.
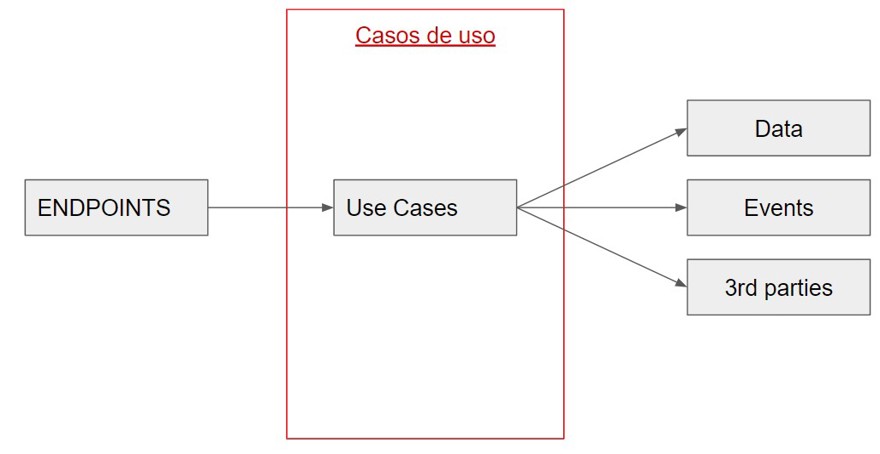
Por ejemplo, si estamos creando clientes en la base de datos, verificamos todos los datos, los insertamos y como último paso publicamos un evento el cual indicara que un evento ha sido creado, todas estas acciones suceden dentro de este caso de uso.
Para mi es importante que esta capa implemente el principio de responsabilidad única. Esto quiere decir que, cada caso de uso, va a realizar una única acción.
Realizar una acción no hace referencia a únicamente validar, o únicamente insertar en la base de datos, hace referencia a todo el conjunto de reglas de negocio necesarias para que algo suceda. Lo que implica que para crear un cliente vas a tener un caso de uso, y para actualizar un cliente vas a tener otro diferente. En C# en concreto eso se traduce en varias clases en vez de tener una enorme que hace muchas cosas.
Ello implica que por la simple forma de trabajar, la api va a cumplir con CQRS, separando las lecturas de las escrituras dentro de nuestra aplicación.
Y cada caso de uso contiene todo lo necesario para funcionar. Por ejemplo, si utilizamos la base de datos inyectamos la base de datos, ya bien sea el dbcontext, o el repositorio si usamos repository pattern o unit of work. Si al terminar el proceso vamos a enviar un evento que notifique que hemos creado un elemento Inyectamos también la interfaz que va a lanzar dichos eventos:
public class AddVehicle(IDatabaseRepository databaseRepository,
IEventNotificator eventNotificator)
{
public async Task<Result<VehicleDto>> Execute(CreateVehicleRequest request)
{
VehicleEntity vehicleEntity = await databaseRepository.AddVehicle(request);
var dto = vehicleEntity.ToDto();
await eventNotificator.Notify(dto);
return dto;
}
}En esta parte utilizó la misma lógica que utiliza la arquitectura hexagonal con los puertos y los adaptadores.
Esta capa de casos de uso es donde mucha gente utiliza Clean Architecture mete el patrón mediador. Si leísteis mi post sobre Clean Arquitectura sabrás mi opinión sobre el patrón mediador, personalmente no lo utilizo porque no aporta nada, especialmente cuando se utiliza mal (handlers llaman a otros handlers) así que lo que yo hago es tener como digo, una clase por caso de uso o acción y luego tener una clase por “grupo” que las engloba.
public record class VehiclesUseCases(
AddVehicle AddVehicle,
GetVehicle GetVehicle);Y pese a que el código esta más acoplado, no lo veo mal pues es un microservicio y no tiene ninguna pega.
Por norma general en esta capa no utilizó interfaces, eso quiere decir que inyectamos al contenedor de dependencias las clases concretas. El motivo es simple, las interfaces en esta capa no aportan valor.
2.3 - Elementos externos
Finalmente la ultima de las capas es donde defino todos los elementos externos de la aplicación, aquí es donde encontramos los motivos por los que debemos utilizar async/await ya que vamos a comunicarnos con los elementos externos de la aplicación.
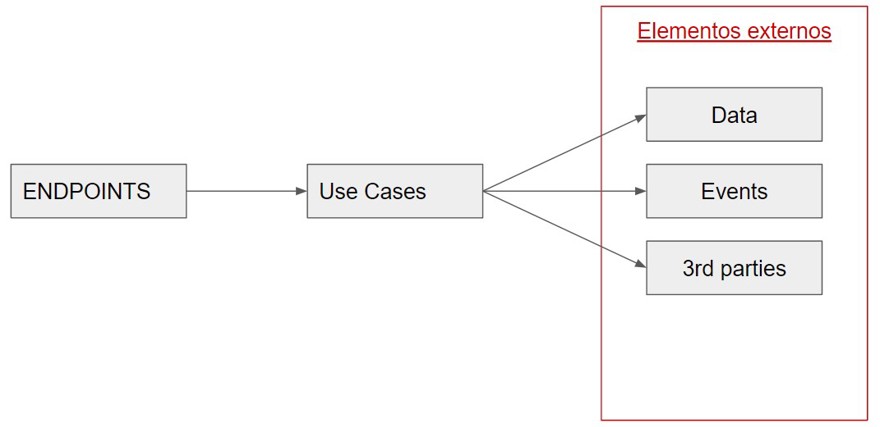
Para mi forma particular de trabajar suelo dividir esta capa en diferentes proyectos dentro de una única solución, para tener una separación clara. Por ejemplo creó un proyecto llamado Data para todo lo que tiene que ver con la base de datos, ya utilice repository pattern o el dbcontext, estará ubicado en este proyecto junto con las entidades de la base de datos.
Si utilizo RabbitMQ para la comunicación de eventos, toda la configuración del rabbitMQ, así como su implementación estará ubicado en ese proyecto en concreto.
Como puedes imaginar, todo el acceso a diferentes partes de la infraestructura o servicios externos va aquí. Puedes utilizar tanto proyectos como carpetas, depende de cuanto vayas a tener y como te guste de forma personal o que estandard tenga tu organización.
2.4 - Inyección de dependencias
Esta arquitectura se basa fuertemente en la inyección de dependencias, ya que vamos a estar inyectando todos los elementos en las capas superiores.
Por ejemplo, inyecto los casos de uso en el controlador e inyecto la base de datos en los casos de uso. Hasta aquí todo normal, pero lo que también hago es declarar todos los elementos que debo inyectar en el proyecto donde están definidos.
Esto quiere decir que dentro de mi proyecto de casos de uso tengo una clase estática con un único método público llamado AddUseCases pero además tengo un método privado por cada grupo de elementos a insertar. Este es el resultado:
public static class UseCasesDependencyInjection
{
public static IServiceCollection AddUseCases(this IServiceCollection services)
=> services.AddVehicleUseCases();
private static IServiceCollection AddVehicleUseCases(this IServiceCollection services)
=> services.AddScoped<VehiclesUseCases>()
.AddScoped<AddVehicle>()
.AddScoped<GetVehicle>();
}
///this in program.cs
builder.Services
.AddUseCases() 👈
.AddData()
.AddNotificator();Luego en la capa superior (API) simplemente invocamos este AddUseCases.
Algo a tener en cuenta aquí, esta configuración está simplificada para mejorar la velocidad y la facilidad con la que se trabaja con dependencias. Hace 5 años cuando empecé con la web cree esta librería que tengo en GitHub y en nuget la cual permite indicar en el proyecto de la dependencia que modulos vas a necesitar y comprueba si están ya inyectados y si no, peta. La idea es buena y funciona (por lo menos hasta NET5) pero creo que no sale a cuenta.
Aunque podrías hacer algo como
var serviceProvider = new ServiceCollection()
.ApplyModule(UseCases.DiModule)
.ApplyModule(Database.DiModule)
.BuildServiceProvider();
// en UseCases:
.AddScoped<UseCaseX>
.RequireModule(Database.DiModule);Lo que hago ahora es la evolución hacia la simplicidad
2.5 - Mejores Prácticas de la Arquitectura Core-Driven
Como punto final, voy a incluir ciertas preferencias que tengo en relación a como hago las aplicaciones.
Personalmente utilizo el patrón Result<T> desde hace más de 5 años, pese a que se ha puesto de moda ahora. El motivo es porque me permite tener un objeto que contiene dos estados, correcto y errado, y luego en la api puedo mapear a un ProblemDetails con el codigo http correcto.
Salvo que la aplicación sea muy pequeña utilizo siempre los controladores “normales” no minimal API, esto es debido a que para hacer APIs compatibles con OpenAPI es mucho mejor, veremos un post al respecto.
Los casos de uso siempre van a devolver un DTO el cual puede salir fuera de la aplicación sin problema, en los casos de uso puedes utilizar entidades, pero nunca devolver una entidad de un caso de uso. Diferencia entre Dto y entidad. Como punto final, los DTO los pongo en un proyecto separado para poder crear un paquete nuget si fuera necesario.
Todas las APIs no deben ser Backend For Front end, entendiendo BFF como una API que recibe una llamada y devuelve toda la información, por ejemplo, tenemos nuestra api de vehículos, donde creamos propiedades de los vehículos como la marca, puertas, color, etc.
El número de vehículos en el almacén es parte del servicio de inventario, no de vehículos. Por lo tanto, si en la interfaz queremos mostrar el número de Vehículos disponibles junto con su nombre etc, tenemos varias opciones.
1 - Llamar desde dentro de la api de vehículos a la de inventario para ver cuantos tenemos disponibles
2- Crear una app BFF que agrupará la información de ambos servicios (o usar GraphQL federated)
3 - Es la Interfaz quien hace ambas llamadas
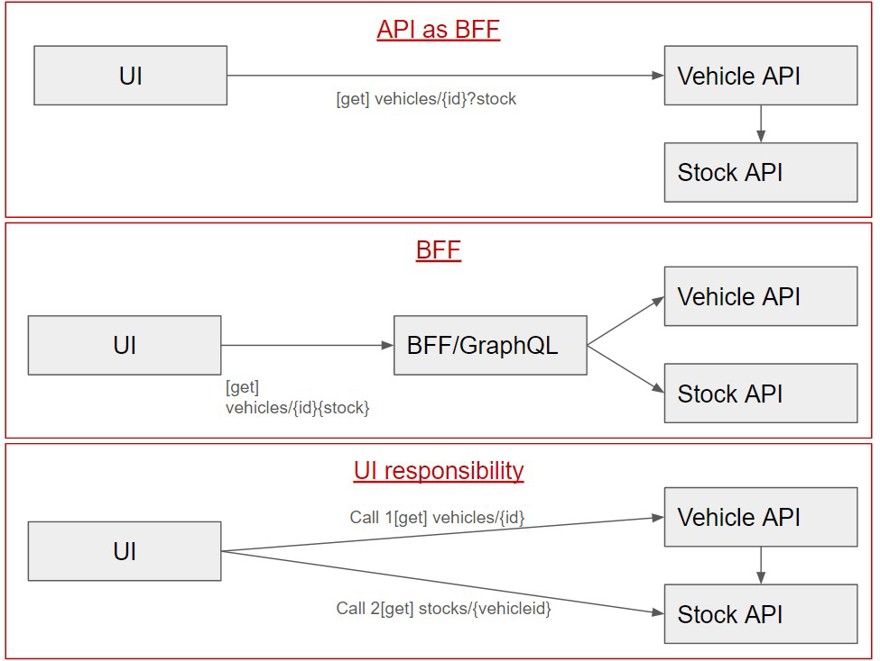
Desde mi punto de vista, la información del stock no es dominio de nuestra API de vehículos, por lo que la primera opción no debería ser una opción válida. Y sobre la opción dos y tres depende de la experiencia de usuario que quieras dar.
El uso de CQRS, cuándo separamos las lecturas de las escrituras, no queremos decir que únicamente podemos consultar a la base de datos, lo que hagamos con la base de datos no tiene nada que ver, lo que hacemos es de cara al consumidor de nuestro caso de uso, si decimos GetVehicle vamos a devolver un vehículo, no vamos a hacer una modificación en la base de datos. Sentido común.
3 - Tests dentro de una Arquitectura Core-Driven
Ya se que vas a estar pensando que los tests no son parte de la arquitectura de una aplicación o lo que quieras.
Pero la realidad es que los test son necesarios así que quería incluir un pequeño grupo. Idealmente deberíamos hacer todos los tipos de tests y tener todo cubierto, etc. Esto no es realista y no siempre es posible. Pero debido a como tenemos la aplicación diseñada es muy muy sencillo tener tests de nuestros casos de uso, los cuales son el core de nuestra aplicación.
Como has podido observar durante este post cada caso de uso tiene un único punto de entrada, lo que implica que únicamente vamos a tener un método que testear, esto no quiere decir que debamos hacer un único test, sino que tendremos un test por cada posible salida de nuestro caso de uso, si estamos utilizando Excepciones como forma de validación debemos validar dichas excepciones. Si Usas Result<T> debes validar cada posibilidad.
public class AddVehicleTests
{
private class TestState
{
public Mock<IDatabaseRepository> DatabaseRepository { get; set; }
public AddVehicle Subject { get; set; }
public Mock<IEventNotificator> EventNotificator { get; set; }
public TestState()
{
DatabaseRepository = new Mock<IDatabaseRepository>();
EventNotificator = new Mock<IEventNotificator>();
Subject = new AddVehicle(DatabaseRepository.Object, EventNotificator.Object);
}
}
[Fact]
public async Task WhenVehicleRequestHasCorrectData_thenInserted()
{
TestState state = new();
string make = "opel";
string name = "vehicle1";
int id = 1;
state.DatabaseRepository.Setup(x => x
.AddVehicle(It.IsAny<CreateVehicleRequest>()))
.ReturnsAsync(new VehicleEntity() { Id = id, Make = make, Name = name });
var result = await state.Subject
.Execute(new CreateVehicleRequest() { Make = make, Name = name });
Assert.True(result.Success);
Assert.Equal(make, result.Value.Make);
Assert.Equal(id, result.Value.Id);
Assert.Equal(name, result.Value.Name);
state.EventNotificator.Verify(a =>
a.Notify(result.Value), Times.Once);
}
}
Aunque es importante que testees cada salida, lo más importante es testear los happy path, en resumen, el camino que el código va a seguir cuando todo va bien.
Como puedes observar utilizo Moq como librería de mock, aunque tienes otras alternativas.
También suelo crear una clase que actúa como “base” sobre lo que es el happy path y contiene las dependencias que van a ser utilizadas.
Y luego cada test describe en el nombre que es lo que hace y que valida.



