En este post vamos a hablar de la generación de identificadores o claves primarias de nuestra base de datos y qué opciones tenemos.
Ínidce
Por supuesto esto es para bases de datos relacionales, en otros tipos de BBDD la opinión sería diferente.
1 - Qué identificador utilizar en una base de datos?
Muchos, yo incluido, hemos tenido siempre la duda de qué forma de crear los IDs de la base de datos tenemos que utilizar. Y hasta hace 10/12 años la verdad que no había duda, es sencillo, utilizamos un ID que va a ser de tipo Int y autonumérico, para que, con cada inserción aumente el valor en 1, pero hace 10/12 años la tendencia empezó a cambiar en favor de los UUID (o GUID en C#).
Como todo en programación cada opción tiene pros y contras, y aquí es lo que vamos a ver, cuando va a ser la mejor opción en cada escenario.
Lo primero que tenemos que ver son las opciones.
2.1 - Qué es un ID autonumérico?
La primera y clara ID int con autoincremento, bastante sencillo de entender, a cada nuevo valor que insertamos se le asigna un identificador numérico secuencial que se incrementa automáticamente; Por defecto empieza de 1 pero ese valor se puede cambiar. Además si tenemos más de una tabla todas las tablas empiezan desde 1, eso quiere decir que el ID 1 de la tabla coches representa un registro mientras que el id 1 de la tabla motos representa uno diferente.
2.2 - Que es un UUID o idetificador único?
La segunda opción es utilizar un UUID, lo que representa Universally Unique Identifier, o en español identificador universal único. Para esta opción quiero hacer hincapié sobre todo en la palabra único, ya que lo que esto significa es que ese ID va a existir únicamente una vez, no solo en tu sistema, sino en el mundo, ya que usa el la hora actual del sistema, una propiedad aleatoria del pc en el que se ejecuta (como la ip pública, la MAC de la tarjeta de red, etc)
Para quien no sepa cómo es un UUID (versión 4, que es el que se usa hoy en día), este es un ejemplo:
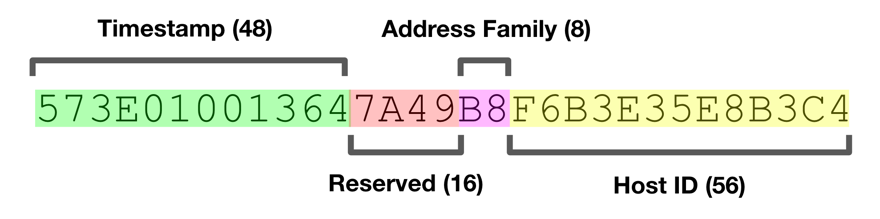
Imagen de https://segment.com/blog/a-brief-history-of-the-uuid/
Técnicamente se puede repetir, pero es muy, muy improbable. Matemáticamente las posibilidades de colisión es de 1 en 2.71 * 10^18, lo cual es un número muy grande, mucho, para tener un 50%de probabilidades de colisión necesitas generar mil millones de UUIDs por segundo durante 85 años.
Vamos que puedes estar tranquilo, si alguna vez pasa (que ha pasado), siempre puedes arreglar manualmente lo que pete y escribes un post al respecto.
Para los que utiliceis C# (como yo), sabed que UUID es lo mismo que GUID, la diferencia es que en Microsoft son un poco especialitos e hicieron su propia implementación…
3 - Pros y contras de utilizar un ID autonumérico
Empecemos por lo más obvio, los IDs autonuméricos son rápidos de consultar, cuando tenemos claves primarias como IDs únicos y hacemos una consulta por ID la base de datos sabe exactamente donde está ubicada dicha información, así que el acceso es el más rápido posible.
Puedes pensar que los UUID también son muy rápidos a la hora de acceder, de hecho postgreSQL tiene un tipo específico para ellos. Y si, es rápido, pero dependiendo de qué nivel de datos tengas en tu tabla puedes empezar a notar problemas con el rendimiento. Aquí no hablo de tablas con un par de millones de registros, sino con miles de millones.
Los Ids autonuméricos tienen la ventaja de que son muy fáciles de implementar, encima se implementan en la base de datos, es la BBDD la que asigna ese valor; aunque esto puede ser un pro y una contra en algunos escenarios, la verdad, sobre todo si necesitas ese nuevo ID de vuelta, si que es verdad que Entity framework nos lo devuevle, pero depende de que base de datos (u orm) utilices, quizá necesites hacer un select después del insert para recoger el ID.
Finalmente si tienes ID autonuméricos, suele ser más fácil mirar a los datos. Me explico, a todos nos ha pasado que tenemos que mirar cosas en la base de datos porque hay algo que no va y no le encuentras el sentido, cuando tienes IDs numéricos es simplemente más fácil de ver, porque son números y no 16 valores completamente aleatorios.
Otro problema muy grande es que al utilizar números es fácil que atacantes o actores maliciosos sepan lo que hacer para intentar hackearte.
De hecho esto ha pasado en dos empresas donde he trabajado. En este caso en particular yo trabajaba en la empresa padre pero estábamos en la misma oficina.
Digamos que un usuario cualquiera tenía acceso a la información de los usuarios de su tenant (como una red social, ver tus amigos, etc), estos usuarios en la interfaz no tenian ID ni nada, pero obviamente cuando llamas al backend el ID iba en el payload, lo mismo para leer. Pues estos atacantes viendo que era un ID autonumérico, cambiaron el ID del payload, y cogieron todos los datos de todos los usuarios en todos los tenants. El backend comprobaba que el que hacía la llamada tenía un token válido, pero luego no comprobaba ni el tenant ni el nivel de acceso).
La cosa no fue a más, de hecho los atacantes fueron dos estudiantes de secundaria que lo utilizaron para ver las notas de sus compañeros 😂; Lo bueno de esto es que la empresa padre en la que yo trabajaba, invitó a los dos chicos a pasar dos semanas gastos pagados en las oficinas de noruega con el equipo de pentesting, para aprender si era lo que les interesaba. La empresa en cuestión es una SaaS que está valuada en 20 mil millones de euros, así que es una oferta muy buena.
4 - Pros y contras de utilizar UUIDs
Si bien es cierto que consultar por UUID no es extremadamente eficiente, tampoco es terrible, además con unos buenos índices se mitiga mucho el problema, así que este apartado lo vamos a dejar en neutro.
Lo que sí que voy a mencionar es que cuando generamos UUID se suele hacer fuera de la base de datos, algunas (que no todas) tienen la funcionalidad de añadir estos valores en el propio insert, pero no es lo más normal, se suele dejar esta responsabilidad al código.
En algunas bases de datos se pueden utilizar UUIDs Secuenciales y es la propia bbdd la que se encarga de generar estos Ids, la ventaja de estos es que no fragmentan el disco que es lo que hace que afecte a la hora de consultar la bbdd, si vas a hacer esto, utiliza Ids autonuméricos, es mi opinion.
Por supuesto la pieza clave aquí es que es imposible de adivinar, bueno no imposible pero prácticamente imposible, así que de primeras no hay problema en devolver estos datos al usuario.
Como he mencionado antes, son identificadores únicos del sistema, si tienes aplicaciones distribuidas o incluso bases de datos distribuidas puedes estar seguro de que los IDS no van a colisionar, un ejemplo puede ser, imaginate que tienes una base de datos por tenant, los IDs de un tenant NUNCA serán iguales que los de otro tenant, lo que puede parecer una chorrada, pero ya te digo yo que no es bonito tener 10 productos con el mismo id, especialmente si tus logs no son muy buenos.
Esto no ayuda simplemente a resolver ese problemas, sino también a temas como la replicación o la migración.
5 - Utilizar ID autonumérico o un UUID como primary key?
La pregunta del millón es cuál debemos utilizar? Primero decir que si tu aplicación es pequeña, puedes ignorar completamente el apartado de rendimiento, por ejemplo este blog utiliza string para muchos IDs, ¿por qué? Porque tengo 200 registros, el rendimiento no cambia.
Lo más importante es saber si vas a devolver esos datos fuera de tu aplicación o no, por norma general, NADA que vaya a ir fuera de tu aplicación, ya sea a la interfaz de usuario, por email, en la URL o en un payload, es buena idea tenerlo como IDs ya que es muy fácil de adivinar, o puedes recibir ataques com el que he mencionado anteriormetne, que en ese caso, tampoco es un hackeo que destruya una empresa, pero puede pasar.
Incluso OWASP recomienda utilizar IDs complejos como programación defensiva; Una opción es ofuscar el ID autonumérico, que si bien es cierto ofuscar un ID no es seguro, es mucho mejor que devolver el ID plano.
No es la única vez que ha pasado en empresas en las que he trabajo, pasó otra vez y despidieron a la persona que lo programó, esa vez fue en la agencia de viajes y se podía acceder a toda la información de los clientes, por no hablar de que lo indexo google…, yo fui el que hizo el siguiente sistema similar a ese, pero sin esos problemas claro 👀.
Yo, personalmente, no devolvería Ids autonuméricos si lo que estoy devolviendo es información sensible. Puedes perder un mínimo, que encima ni se nota, en rendimiento, pero ganas en salud.
5.1 - Combinar IDs numéricos y UUIDs
También he visto combinar ambas, de cara al usuario devolver siempre el UUID, pero luego internamente para las relaciones entre tablas utilizar.
No soy el más fan del mundo, pero no es mala idea, especialmente si tienes muchos joins en las diferentes tablas de la base de datos.
5.2 - Squids en .NET
Finalmente, como alternativa tenemos los Squids esto no es mas que una librería que te permite generar identificadores únicos a partir de números, lo que hace que sean seguros para la URL;
Piensa en youtube por ejemplo, el identificador de los vídeos es muy probable que Youtube por detrás tenga un ID autonumérico.
Este Id es puramente visual y es muy fácil de utilizar, tanto a la hora de encriptar como a la de desencriptar, unicamente hay que hacer lo siguiente:
var sqids = new SqidsEncoder<int>();
var id = sqids.Encode(1, 2, 3); // "86Rf07"
var numbers = sqids.Decode(id); // [1, 2, 3]
Si tienes más curiosidad al respecto puedes navegar por su página de GitHub donde tienen mucha mas información al respecto, como por ejemplo proporcional un diccionario de caracteres, para que así sea muy dificil de descenriptar, bloquear ciertos caracteres, o consecución de caracteres, etc.



