Alguna vez te has preguntado qué hay detrás de todos los sistemas para reducir una url?
En este post veremos la arquitectura de dichos sistemas. Lo que es una pregunta muy común dentro de entrevistas de diseño, y esta en concreto se podría identificar como un nivel fácil.
Índice
1 - Requerimientos de un sistema acortador de URL
Donde primero debemos parar a pensar es en los propios requerimientos que vamos a necesitar para poder tener una aplicación o sistema completo.
Este tipo de aplicaciones, tiene una funcionalidad principal:
Cuando pulsas en una URL corta, te redirige a otra completamente distinta.
Junto con esta funcionalidad principal, vienen dos características principales:
- Esta URL debe ser corta, pues es en lo que se basa nuestra aplicación.
- La aplicación debe estar siempre disponible (99.9999% uptime) e ir rápida (<200 ms).
Esos son los requerimientos principales, pero hay otros que existen y no son tan visibles a simple vista. En una entrevista siempre va a ser beneficioso mencionar varios puntos, aunque en la mayoría de casos no te van a requerir que vayas más allá:
- Dos URL no se pueden repetir.
- Detectar URL Maliciosas.
- Alias personalizado, en vez de generar una url automática, el usuario puede poner un alias, aunque sea más largo.
2 - Diseño de la API
Una vez tenemos los requerimientos vamos a pasar a la creación de la propia API. En este caso tendremos que mencionar/definir o dibujar (depende donde hagas la entrevista) todos los endpoints clave de nuestra API. En este caso tenemos cuatro, por lo que vamos a definirlos todos.
POST /urls: crear una nuevo recurso (un recurso, en este caso es una URL)GET /{short-url}: Lee un recurso y redirecciona a la URL originalPUT /urls: modifica un recrusoDELETE /{short-url}: Elimina un recurso
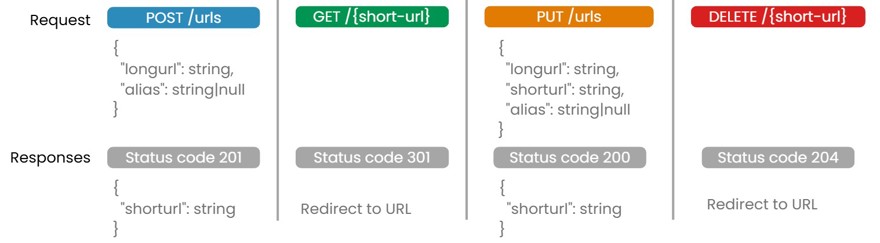
Cosas a tener en cuenta de este diseño.
En el PUT /urls, se podría debatir que clase de modificación quieres que sea posible, si modificar la URL corta con un nuevo alias sería posible o esa acción sería simplemente creando una nueva URL. O incluso podrías debatir si se debe poder modificar una URL o una vez se crea debe ser inmutable.
Recuerda que nunca hay una solución correcta y otra errónea. Lo realmente importante es que seas capaz de debatir las diferentes opciones.
2.1 - Código de estado HTTP para una redirección
Dentro de nuestro método GET vamos a redireccionar a otra URL, por lo que debemos indicar el código de estado correcto en la respuesta de nuestra aplicación. Para ello tenemos dos opciones.
- Código de estado 301 para redirección permanente. En nuestro caso, siempre que la URL esté en el sistema vamos a redireccionar, lo que implica que vamos a devolver un 301.
- Código de estado 302 para la redirección temporal. En otros sistemas podemos tener una redirección temporal. En nuestro sistema actual, podríamos modificar el sistema para que tenga una fecha límite (campo DateTime) de hasta cuando queremos esa URL que redireccione, en ese caso utilizaremos 302. Este punto es importante mencionarlo si estás haciendo una entrevista.
Algo a tener en cuenta es que cuando haces un 301 el navegador hace caché de la propia redirección. Ello implica que aunque el usuario pulse en el enlace, la llamada nunca llegará a nuestro sistema, lo que puede no ser ideal en un entorno de producción real, ya que estos enlaces muchas veces van enlazados a analíticas y estadísticas de uso, región, etc.
Mencionar que si el formato que vais a ver os gusta, os gustará también mi libro Construyendo Sistemas Distribuidos, donde vemos muchos de los temas que se tocan en este post en profundidad.
3 - Diseño de la arquitectura de un Acortador de URL
Lo primordial a la hora de crear diseños es empezar con el caso de uso más básico, y de ahí ir evolucionando la solución, de esta forma, sobre todo si estamos en una entrevista vamos teniendo tiempo para pensar y conversar con el entrevistador.
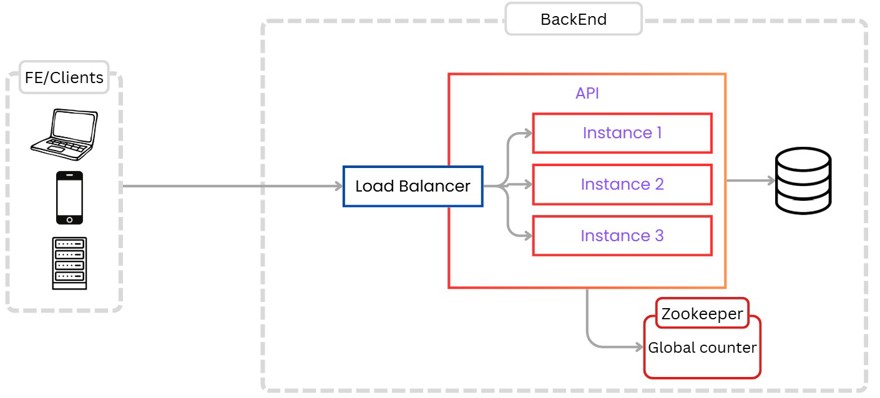
Para nuestro primer requerimiento necesitamos que un usuario sea capaz de crear links, además por supuesto de leer, actualizar y eliminar. Para ello creamos una solución simple.
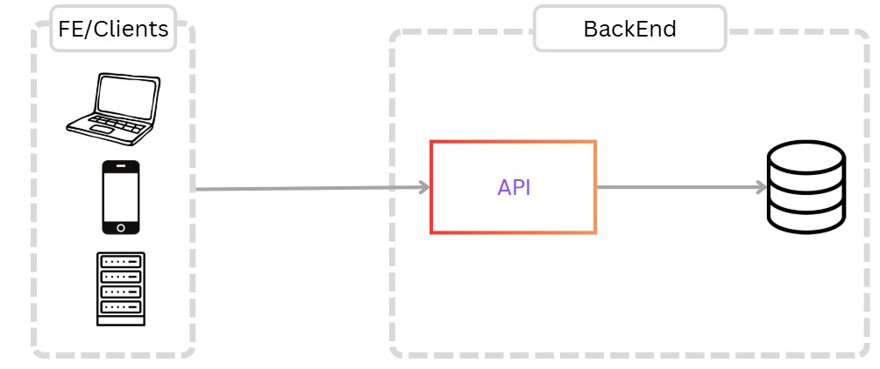
En esta solución tenemos las siguientes entidades:
- Los clientes, ya sea la interfaz o un cliente externo que llaman a nuestra API.
- Una única instancia del código, la cual se encarga de todas las operaciones.
- La base de datos.
Además, pese a no estar dibujado, también tenemos administración de usuarios para crear/actualizar los enlaces.
El proceso es muy sencillo, un usuario hace una llamada a la API, la cual crea el registro en la base de datos y se lo devuelve al usuario.
Si el usuario ha enviado un alias, o incluso si hemos implementado el campo de la fecha límite también tendremos que tenerlo en cuenta a la hora de crear un registro.
En el caso de leer, hacemos lo mismo, el usuario hace el get con la URL corta y de ahí lee la base de datos y recibe la URL real con el código de estado 301 (Permanent Redirect) o 302 (found redirection).
Como solución sencilla o como MVP nos puede servir esta arquitectura simple, pero obviamente no podemos parar aquí, ya que tenemos más requerimientos.
3.1 - Para crear URLs cortas, ¿Qué caracteres utilizamos y cuántos?
Una solución muy común para este tipo de situaciones es el uso de base62. Y por qué te puedes preguntar? Muy sencillo, igual que base 10 son los números del 0 al 9, cuando hablamos de base 62 utilizamos los número del 0 al 9 así como las letras A-Z y a-z, osea todo el abecedario, tanto en mayúsculas como en minúsculas. Lo que significa que reduce muchísimo el número de caracteres que vamos a utilizar si convertimos un numero en base 10 a base 62.
Por ponerte un ejemplo, el número de base 10 con el valor 123456789 tiene un valor en base62 de 8M0kX.
Ahora que tenemos claro el rango [0-9][A-Z][a-z] tenemos que ver el tamaño de URL que necesitamos. Para ello, debemos calcular y comparar las diferentes opciones. Y es muy sencillo, solo tenemos que elevar 62 al número de caracteres objetivo para saber cuántas combinaciones posibles tenemos.
Por ejemplo, una url de un solo carácter nos daría 62 opciones diferentes, mientras que dos caracteres serían 62^2 serían 3844, lo cual no parece suficiente.
Pero veamos otras opciones:
62^1 = 62
62^2 = 3844
..
62^6 = 56 mil millones de URLs
62^7 = 3.5 trillones de URLs
62^8 = 218.3 trillones de URLsComo puedes ver, cada vez que añades un carácter extra las cantidades crecen exponencialmente y el valor que posiblemente queramos esté entre el 6 y el 8, el 6 parece poco, y por un poco más podemos simplemente usar 7 caracteres ya que el 8 es muy grande.
Lo más posible es que nuestro servicio nunca llegará a un número tan largo.
Nota adicional: Si usas C#, Si utilizas unsigned int el número máximo es 4,294,967,295, cuatro mil millones, que cabe en 6 caracteres. pero siempre tienes la opción de utilizar unsigned long, donde el máximo número que se permite es 18,446,744,073,709,551,615 (18 quintillion) el cual en base 62 tiene 11 caracteres (LygHa16AHYF)
Vamos a asumir que con 7 tenemos suficiente y el motivo es sencillo, 3.5 trillones es este número: 3500000000000 y en un año tenemos 31.5 millones de segundos(31,536,000) lo que significa que necesitamos casi 110 años a 1000 creaciones de por segundo para completar todos los registros, por lo que no va a suceder nunca.
3.2 - Llevar el conteo de URLs
En el punto anterior hemos visto que caracteres vamos a utilizar y cuantos, ahora viene el momento de generar dichos valores.
Una solución podría ser que generase un número aleatorio, hiciera un hash cortando a 7 caracteres. Y ese valor sería el que guardaremos en la base de datos.
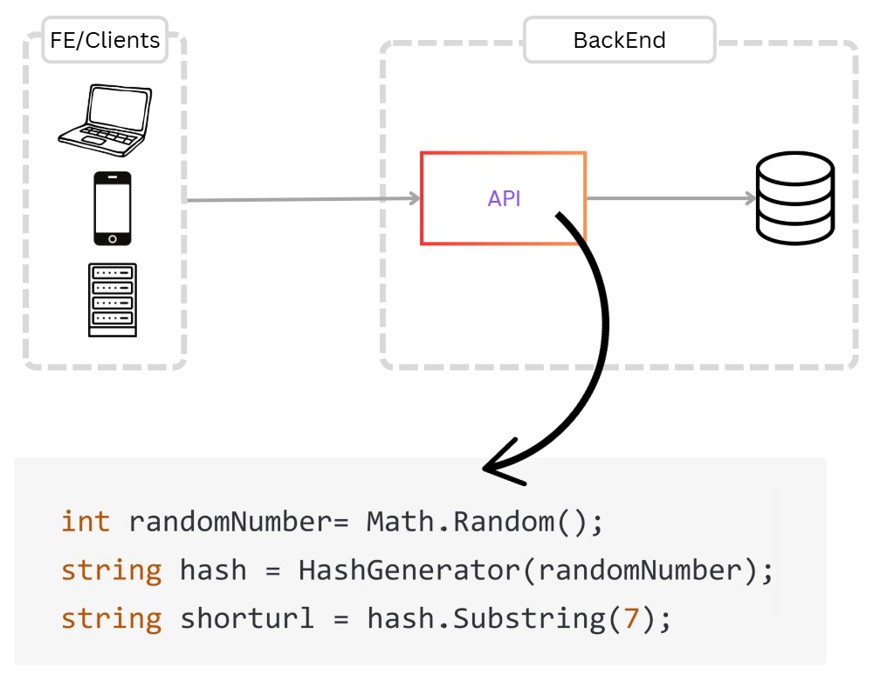
Pero esa solución es muy posible que tenga colisiones en algún momento, quizá no en nuestro tiempo de vida, pero técnicamente es posible que si las tenga.
La mejor solución en este aspecto es utilizar un Service-coordinator donde tenemos varias opciones. Una muy común es Redis ¿Por qué? Redis es una caché distribuida single-threaded lo que significa que realiza una acción cada vez y por ello nunca vamos a tener colisión.
Pero una solución aún mejor, es utilizar un servicio dedicado a ello como puede ser Zookeeper el cual se encarga de toda la asignación de valores de forma correcta y por si solo.
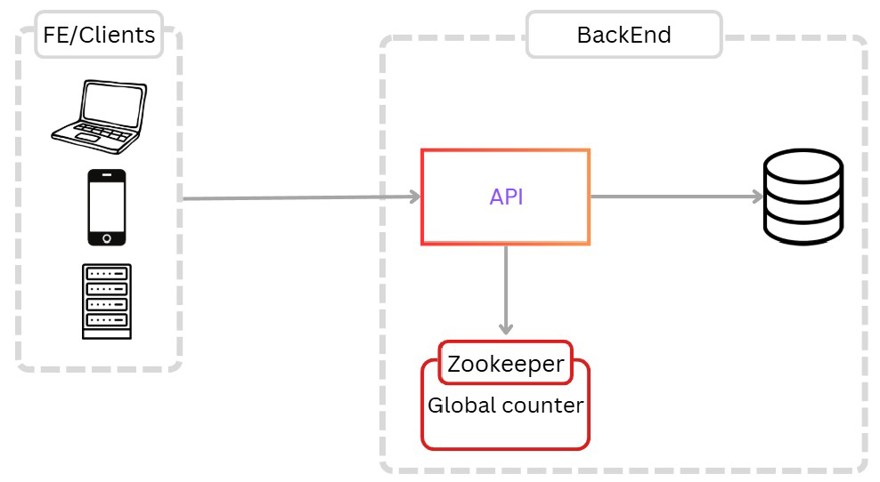
El motivo principal es que a la hora de escalar se puede complicar el asunto, sobre todo si tenemos que escalar el Redis, requerirá de bastante configuración y tal para no dar IDs repetidos a las instancias que los piden.
Por ello utilizaremos una práctica o patrón que denominamos counter-batching, donde cuando una instancia inicia el servicio, este se conecta al service-coordinator y le devuelve un rango de IDs con los que va a operar.
Por ejemplo, la instancia 1 trabaja entre el rango 1 y el 1.000.000, de esta forma mantenemos en memoria el rango actual sin tener que hacer llamadas al coordinador cada vez. Cuando la instancia 2 se conecta, redis le da el rango 1.000.001 y el 2.000.000, y así sucesivamente. Cuando hemos llegado al máximo, volvemos a consultar a redis para hacer dos operaciones, la primera, indicar que ese rango está completo, y la segunda recibir un nuevo rango.
Por supuesto el coordinador ya sea redis, zookeeper, o el que queramos, únicamente nos devolvería el rango en base 10 a utilizar, la conversión a base 62 la haríamos en cada una de las instancias.
3.3 - Escalado de una aplicación de Acortamiento de URLs
El escalado es algo importantísimo hoy en día en los servicios en la nube, ya que nos permiten mantener siempre el coste de correr la infraestructura al mínimo, pero para ello debemos ser capaces de identificar de forma automática cuando escalar nuestras aplicaciones de forma vertical u horizontal. Para nuestro caso en concreto lo mas normal sería escalar de forma horizontal, añadiendo más instancias.
Pero para nuestro caso en concreto la cosa no acaba ahí ya que por la naturaleza de la aplicación, nuestro volumen de lecturas va a ser mucho mayor que nuestro volumen de escrituras.
Como ejemplo podemos poner twitter, que ya no acorta los enlaces pero antiguamente lo solía hacer y vamos a un tweet cualquiera del Betis:

Este tweet ha sido escrito una única vez, para ello se ha creado una llamada POST con el enlace y devuelve el enlace corto.
Al momento que hice la captura, ese tweet lo habían visto 9400 personas, asumiendo que únicamente el 0.1% ha hecho click, eso ya son 9 personas que han visitado el enlace. Con lo que podemos asumir tranquilamente un uso de la parte de lectura 10 veces superior a la parte de escritura.
Lo que quiere decir que es posible que nos interese dividir la API en dos, una para hacer lecturas y otra para hacer escrituras.
Además, a la hora de hacer las lecturas también estaremos escribiendo en una caché distribuida de redis los valores de la redirección de la URL. Así, las siguientes llamadas que se generen no se hacen sobre la base de datos, sino que se hacen sobre redis lo cual es mucho más rápido y requiere menos recursos.
El proceso final sería algo como lo siguiente:
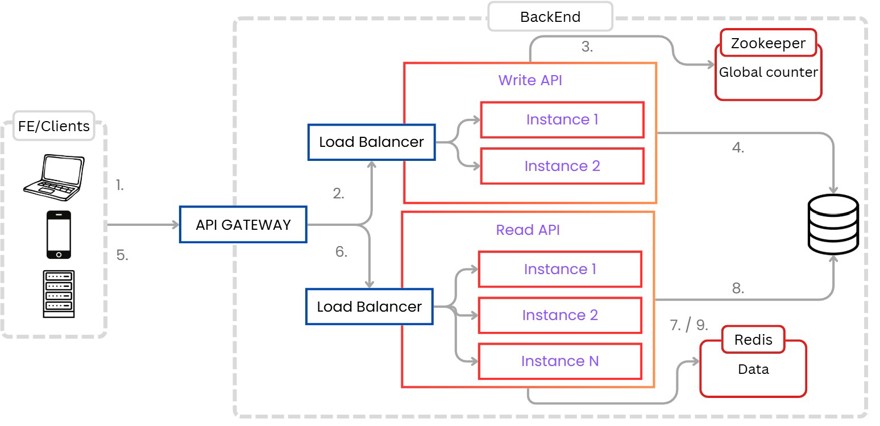
A la hora de crear nuevos recursos el proceso el siguiente:
1 - El cliente realiza la llamada a la API Gateway.
2 - Al ser método POST, utilizaremos el Load Balancer de la api de lectura y asigna una instancia.
3 - Recibimos del Coordinador el rango, o si lo tenemos, calculamos el siguiente valor
4 - guardamos el registro en la base de datos y devolvemos la URL corta.
4.1 - opcionalmente podríamos guardar en el redis distribuido que tiene los datos de las urls la nueva que hemos creado.
Una vez creado, pasamos al acceso a dicha URL.
5 - El usuario hace click en el enlace y va a la API Gateway
6 - Al ser GET, vamos al Load Balancer de la API de lectura.
7 - Comprobamos si el registro está en Redis.
8 - Si no lo está, leemos el registro de la base de datos
9 - Añadimos el registro en Redis y devolvemos el valor de la url larga, haciendo uso del código de estado 301 ó 302 para una redirección del usuario.
Finalmente, podríamos mencionar que cuando guardamos en la caché lo hacemos con un TTL específico, para que la caché no sea una copia 1 a 1 de la base de datos, sino que tenga los valores más necesitados.
Un ejemplo es especificar un TTL de dos días, ya que por ejemplo en el caso de twitter que hemos visto la gran mayoría de clicks van a venir en los primeros días, al cabo de una o dos semanas no va a pulsar nadie.
Con esto ya tendríamos la arquitectura completa de un sistema de acortamiento de URLs.


