Escribo este post principalmente porque estoy cansado de leer que si Odata es mejor o peor que GraphQL, que si nosecuantas cuando la verdad es que ambas soluciones NO deberían ser comparadas, ya que solucionan dos problemas diferentes.
Índice
En este post no voy a pararme en las características al detalle de cada uno de estas tecnologías, para eso veremos post individuales, de GraphQL seguro, y posiblemente cree alguno de OData también. Este post es para mostrar donde brilla el uso de OData como el uso de GraphQL.
1 - Qué es OData?
En términos simples, Odata es una librería que la ponemos en nuestra api y nos permite hacer llamadas rest para consultar únicamente la información que necesitamos.
Vamos a imaginarnos que tenemos una app, y en la versión web imprimimos los detalles del usuario, tipo, nombre, apellidos, id, dirección, etc. Pero en la versión móvil, únicamente imprimimos el nombre y el apellido. Técnicamente, para la versión móvil, podríamos utilizar la misma request que para la versión web.Pero si tenemos miles o cientos de miles de requests, los datos extra que estamos devolviendo pueden suponer mucho coste monetario, especialmente porque los descartamos.
Ahí entra Odata, en vez de tener que hacer dos Endpoints diferentes, podemos utilizar OData, que crea dichos endpoints automáticamente y simplemente indicar los elementos o propiedades que necesitamos de dicho objeto u objetos.
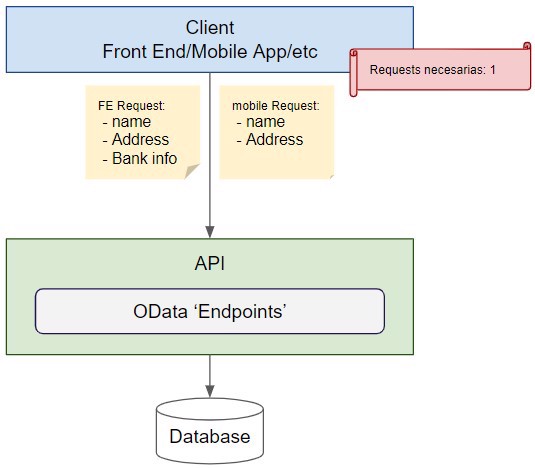
Ambas request van “al mismo endpoint”, además nos permite devolver objetos que están enlazados dentro del objeto principal o hacer queries de otros objetos a “root” level.
Si en este ejemplo no tuviéramos OData, lo más probable es que tuviéramos que hacer una llamada para los datos del usuario, otra para los datos bancarios, etc.
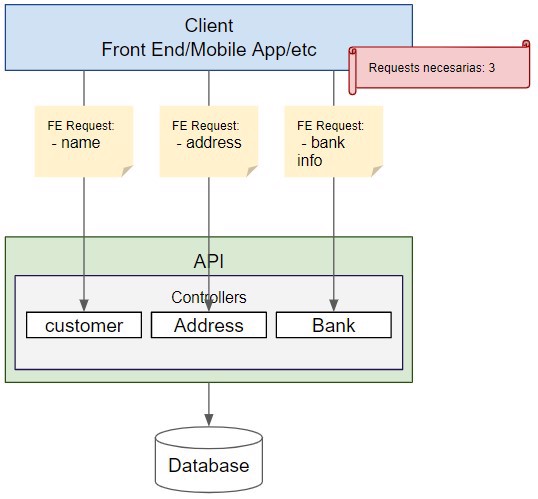
Por supuesto esto también implica que devolvemos mucha más información de la que necesitamos. Lo cual como siempre, si son unas pocas llamadas no hace daño, pero si son cientos o miles, si.
Por cierto, OData, permite definir todas las operaciones CRUD (Crear, Leer, Actualizar, Eliminar), así como filtrar, ordenar, y paginar datos.
Antes de terminar con Odata, cuando no se utiliza OData, se suele tener un endpoint en el back end que cubre todas las necesidades del front, como hemos visto, con OData no es necesario, o bueno nos suple esta necesidad, ya que OData por sí mismo es muy potente.
2 - Qué es GraphQL?
Igual que en el caso anterior, no voy a entrar en detalles, sino una primera toma de contacto. GraphQL es un lenguaje de consulta que nos permite definir la estructura de datos en la parte del cliente, Osea, un cliente pide los datos que necesita, y así ahorramos en la transferencia de datos.
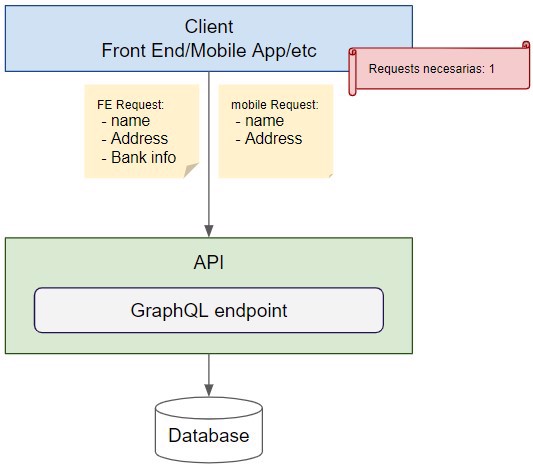
como vemos en la imagen es, arquitecturalmente, igual que OData, entonces, porque digo que no son comparables?
3 - Odata VS GraphQL, Cuál elegir?
Visto lo que acabamos de ver, en verdad si los estamos comparando, no?
Bueno la realidad es que no son comparables, o no deberían, principalmente por un par de elementos, que van a ser claves.
OData es una librería que va en tu aplicación, de forma individual, y automáticamente mapea la base de datos a endpoints REST.
Pero claro, ¿qué pasa en el mundo de los microservicios? qué sucede si tenemos la información muy separada, Para volver al caso de antes, qué sucede si tenemos la información del banco en un microservicio separado?
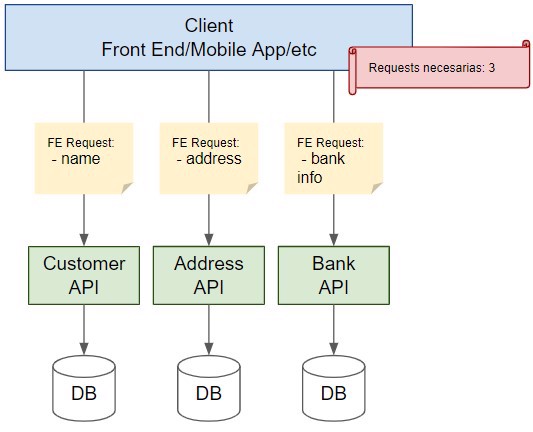
La respuesta es clara, tenemos que hacer dos llamadas diferentes, lo que potencialmente nos puede retrasar a la hora de mostrar los datos al usuario, dependiendo de la complejidad de dichas llamadas, obviamente.
Por lo tanto, con esta información, nos damos cuenta que, OData, funciona muy bien en un entorno donde tenemos un monolito o un monolito modular pero no tan bien en entornos de microservicios.
Ahora vamos a pasar a GraphQL, como OData, GraphQL es una librería que va en tu API de forma individual, PERO tiene una gran diferencia con Odata, GraphQL crea lo que se denomina un schema, y este schema es leído por un supergraph y combinado con el resto schemas, crean un grupo de subgraphs, lo que hace, que de cara al Front end sea una única request, ya que lo que hacemos es llamar al supergraph.
Es el supergraph/Gateway la que se encarga de detectar de donde puede conseguir dicha información, consultarla y montarla para devolvérsela al usuario.
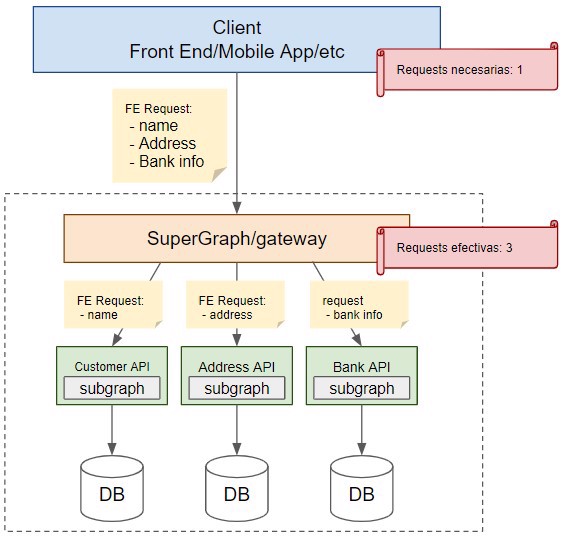
Por supuesto, para que todo funcione correctamente, la configuración de los schemas tiene que estar bien montada, tema tipos/objetos, etc, ya que es lo que va a utilizar para detectar cuando un objeto está separado en múltiples microservicios.
3.1 - Cuándo utilizar OData o GraphQL?
Finalmente mi opinión después de haber trabajado con ambos (Con OData solo una PoC) es que GraphQL es muy potente, y muy cool, pero se usa demasiado en sitios donde no hace falta, ni se necesita.
Quiero decir, arquitecturas enteras que tienen comunicación con el Front End 1 - 1 con las API, simplemente añade una capa extra de complejidad. Si este es tu caso, NO necesitas GraphQL, si tienes microservicios bien montados, y las requests son buenas, GraphQL puede ser el mayor descubrimiento para tu aplicación.
Y Odata tiene la facilidad de con un par de líneas de código, darte acceso a toda la base de datos a través de una API Rest, que dependiendo en qué estado de la aplicación esté, es muy potente, además de que tiene más opciones que GraphQL como el filtrado, ordenar, etc, Si quieres hacer filtrado u ordenación con GraphQL tienes que hacerlo por código de forma manual.
Como puedes ver, ambas opciones pueden parecer alternativas a primera vista, pero no lo son, ya que nos solucionan dos escenarios completamente diferentes.



